UM-CV 12 & 13 Recurrent Neural Networks & Attention Mechanism
Part 1: RNNs, Vanilla Rnns, LSTMs, GRU, Gradient explosion, Gradient vanishing, Architecture Search, Empirical Understanding of RNNs.
Part 2: Seq2Seq, Attention Mechanism, Self-Attention, Multi-head Attention, Transformers, Scaling up Transformers.
@Credits: EECS 498.007 | Video Lecture: UM-CV 5 Neural Networks
Personal work for the assignments of the course: github repo.
Notice on Usage and Attribution
These are personal class notes based on the University of Michigan EECS 498.008 / 598.008 course. They are intended solely for personal learning and academic discussion, with no commercial use.
For detailed information, please refer to the complete notice at the end of this document
Intro
Process Sequences
- one to one: standard feed-forward network
- one to many: image captioning
- many to one: sentiment analysis, image classification
- many to many: machine translation/per-frame video classification
Sequential Processing of Non-Sequential Data
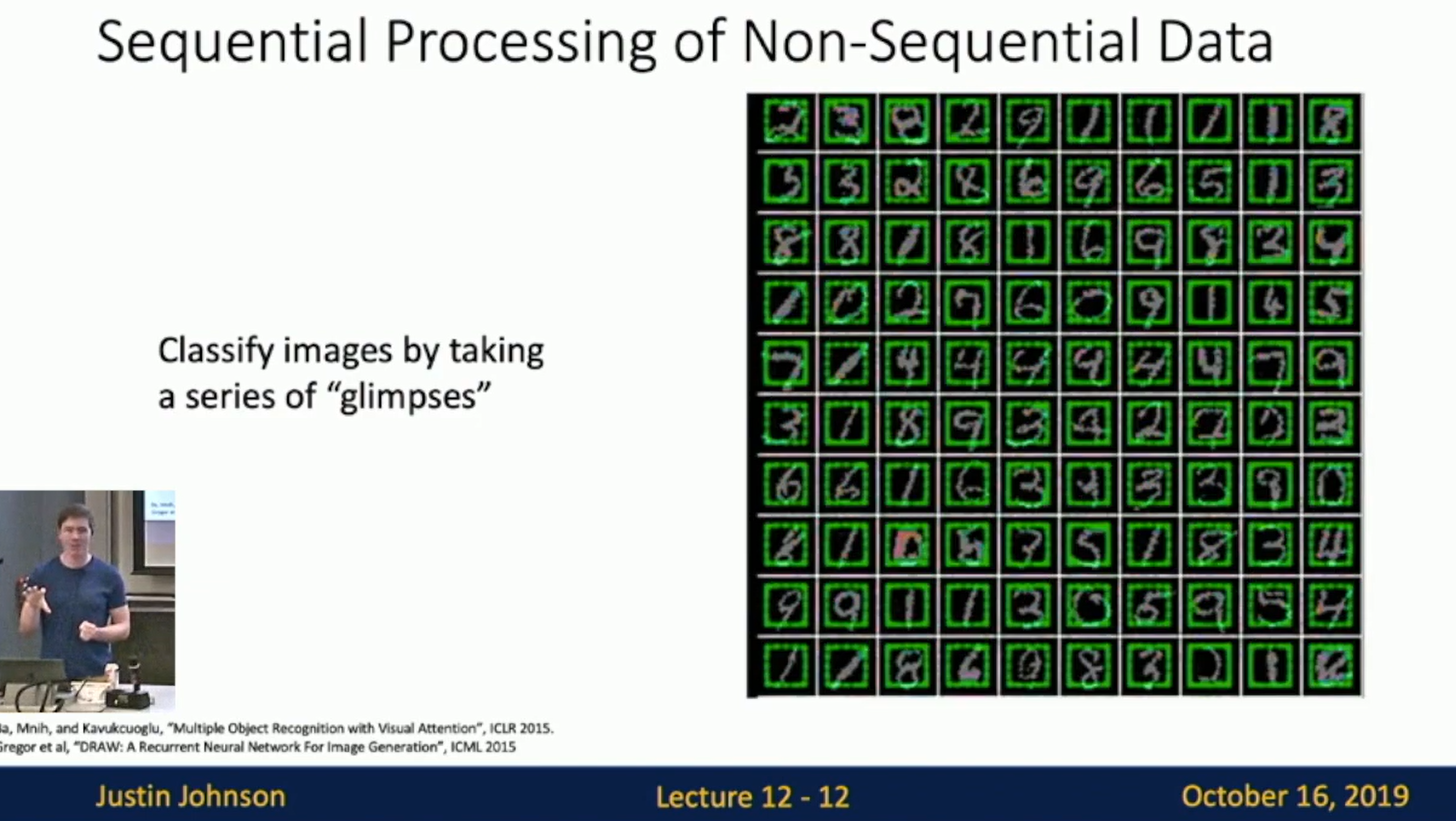
Sequential Processing of Non-Sequential Data: Classification

Sequential Processing of Non-Sequential Data: Generation
Recurrent Neural Networks
Architecture
Key idea: RNNs maintain a hidden state that is updated at each time step.
where is the hidden state at time , is the input at time , and is a function parameterized by .
Vanilla Recurrent Neural Networks:
Computational Graph
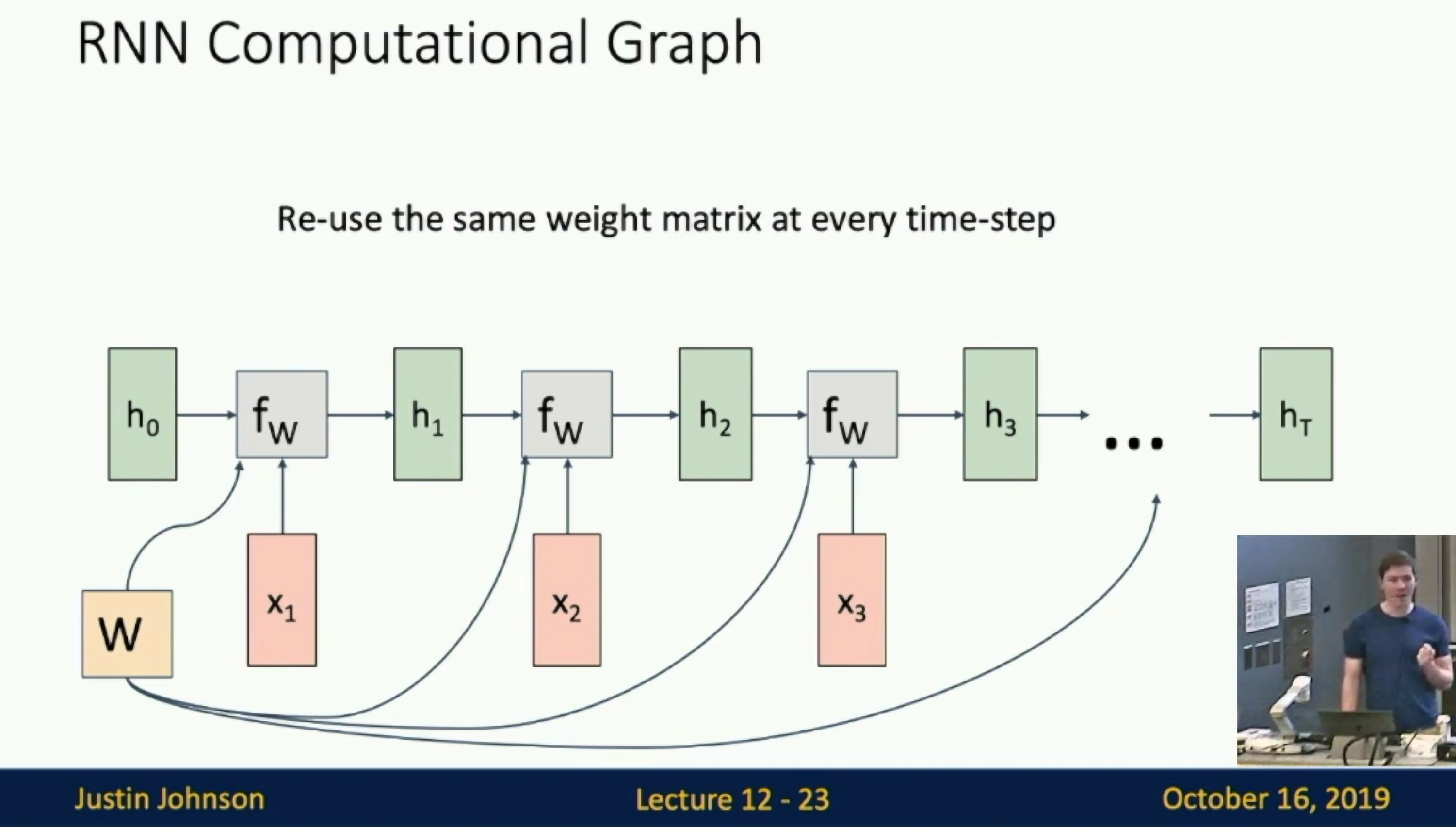
Computational Graph of RNN
Many to many:
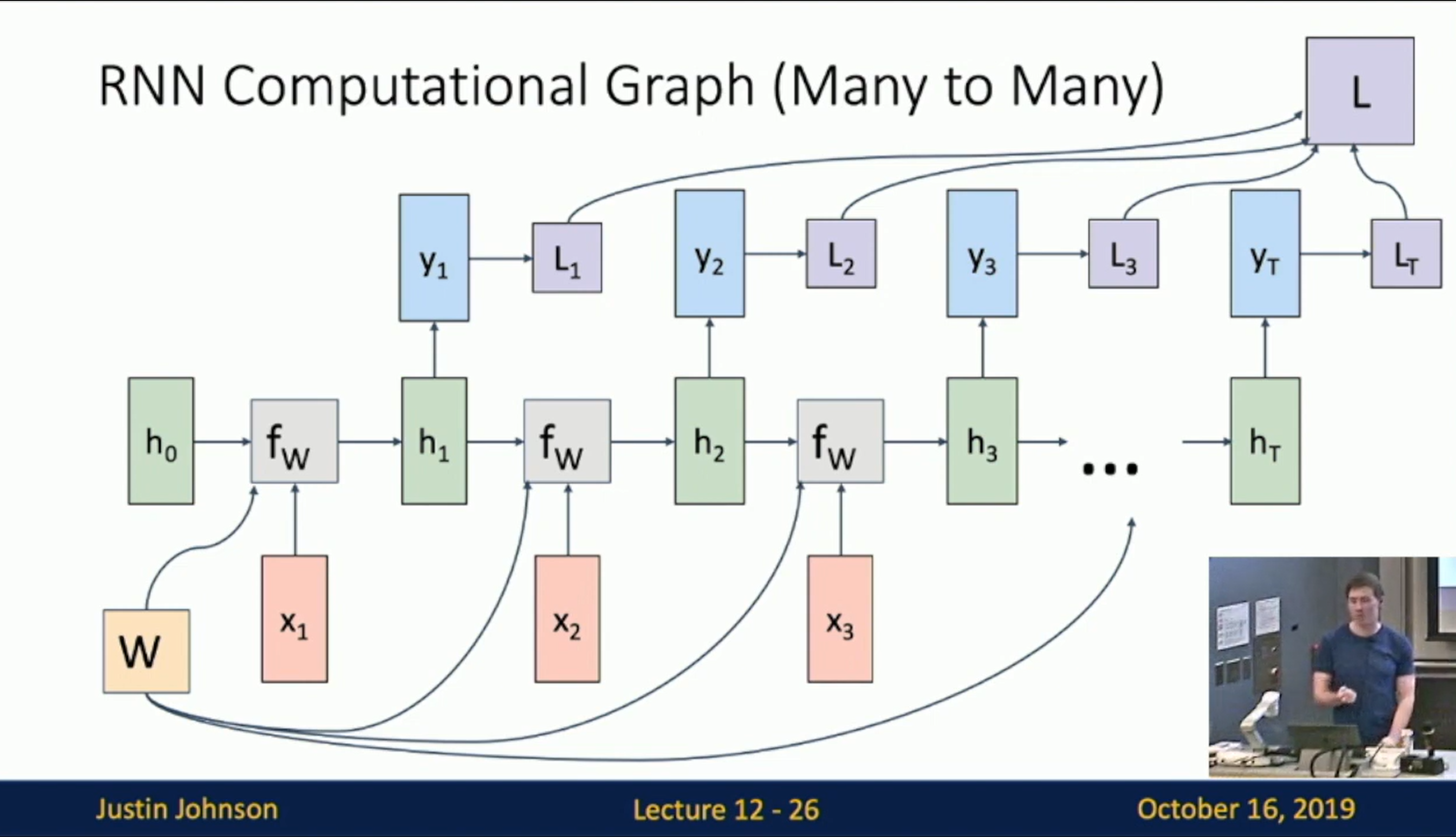
Computational Graph of RNN: Many to Many
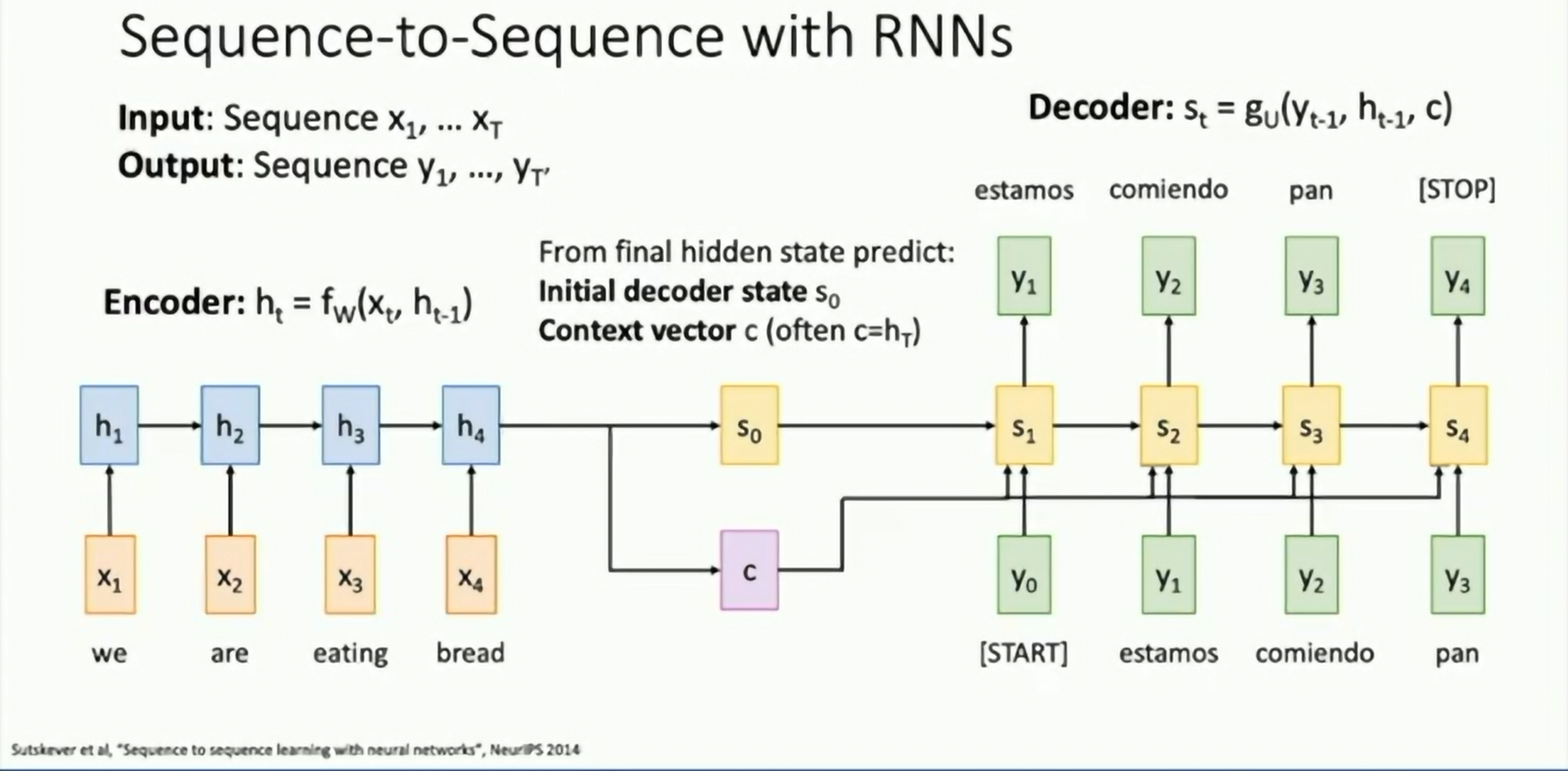
Many to one: Encode input sequence in a single vector. See Sequence to Sequence Learning with Neural Networks.
One to many: Produce output sequence from single input vector.
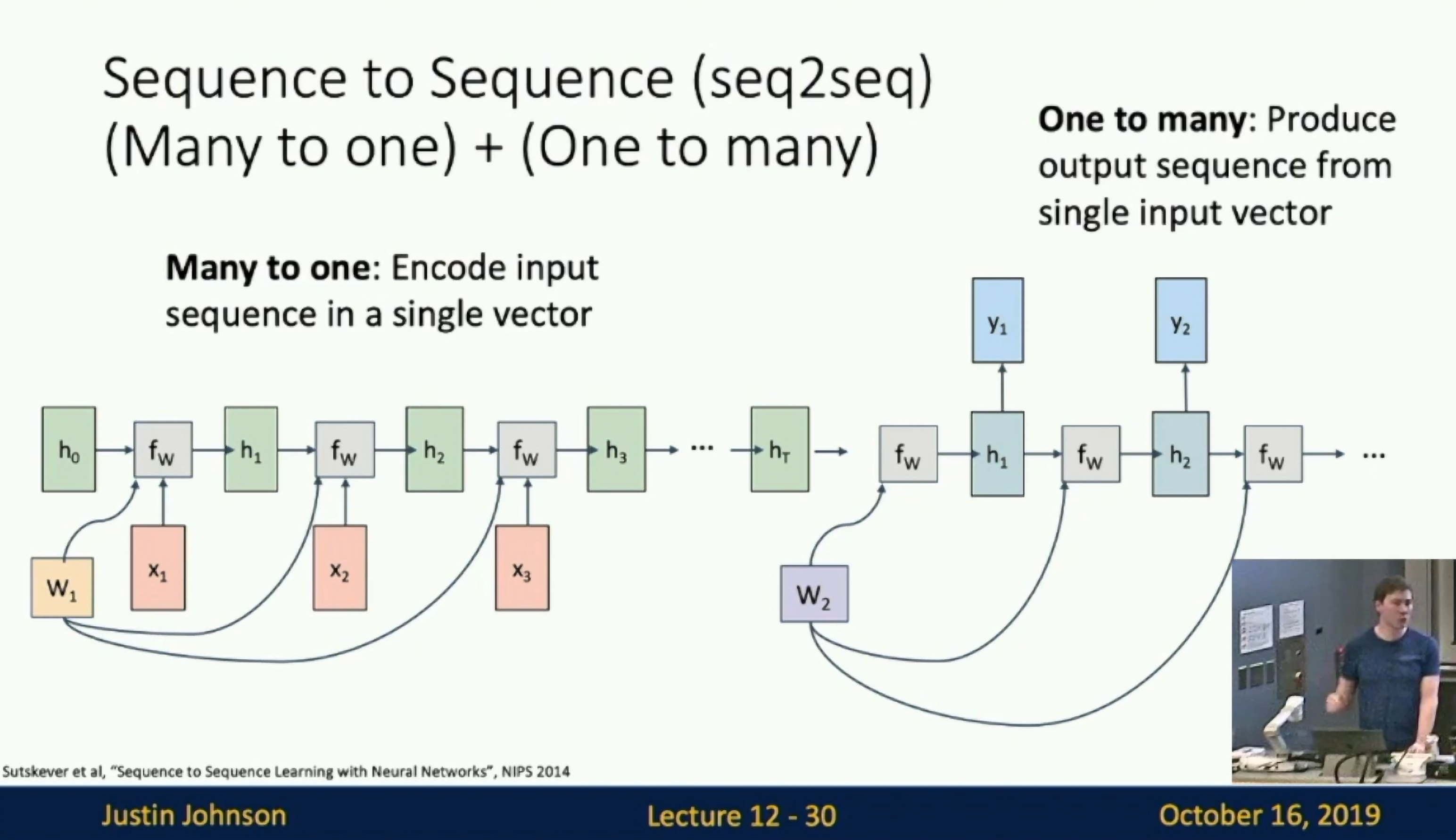
Seq2Seq
Example: Language Modeling

Language Modeling
Given "h", predict "e", given "hell", predict "o".
So far: encode inputs as one-hot-vector -> Embedding layer
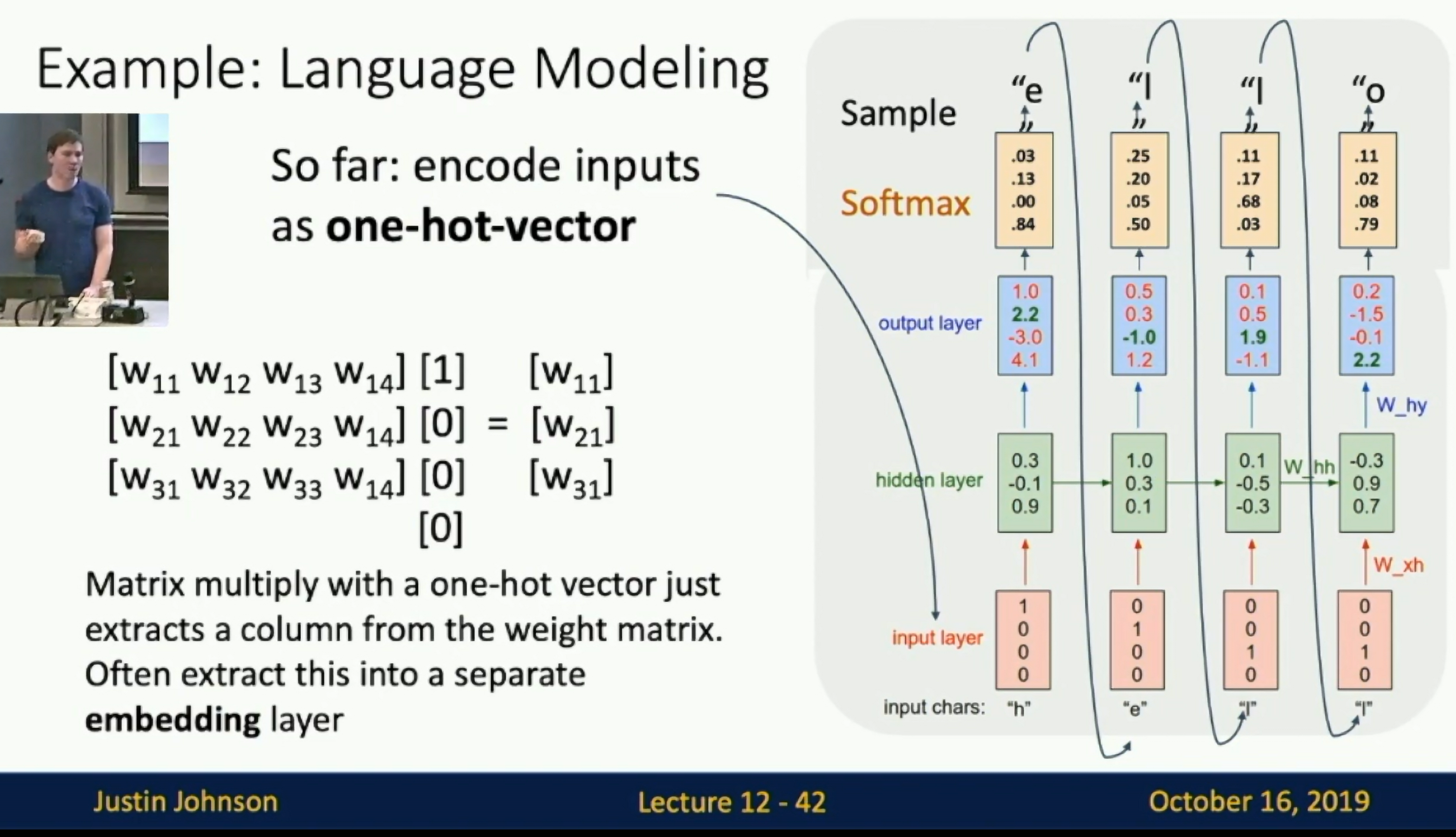
Embedding layer
Backpropagation Through Time
- Problem: Takes a lot of memory for long sequences.
- Unroll the RNN for a fixed number of time steps.
- Solution: Truncated chunks of the sequence.

Backpropagation Through Time
Minimal implementation: min-char-rnn.py
Training RNNs
Shakespeare's Sonnet, Algebraic Geometry Textbook LaTeX code, Generated C Code

Training RNNs
Searching for Interpretable Hidden Units
Visualizing and Understanding Recurrent Networks: arXiv:1506.02078

Quote deletion cell

line length tracking cell

If statement cell
Example: Image captioning
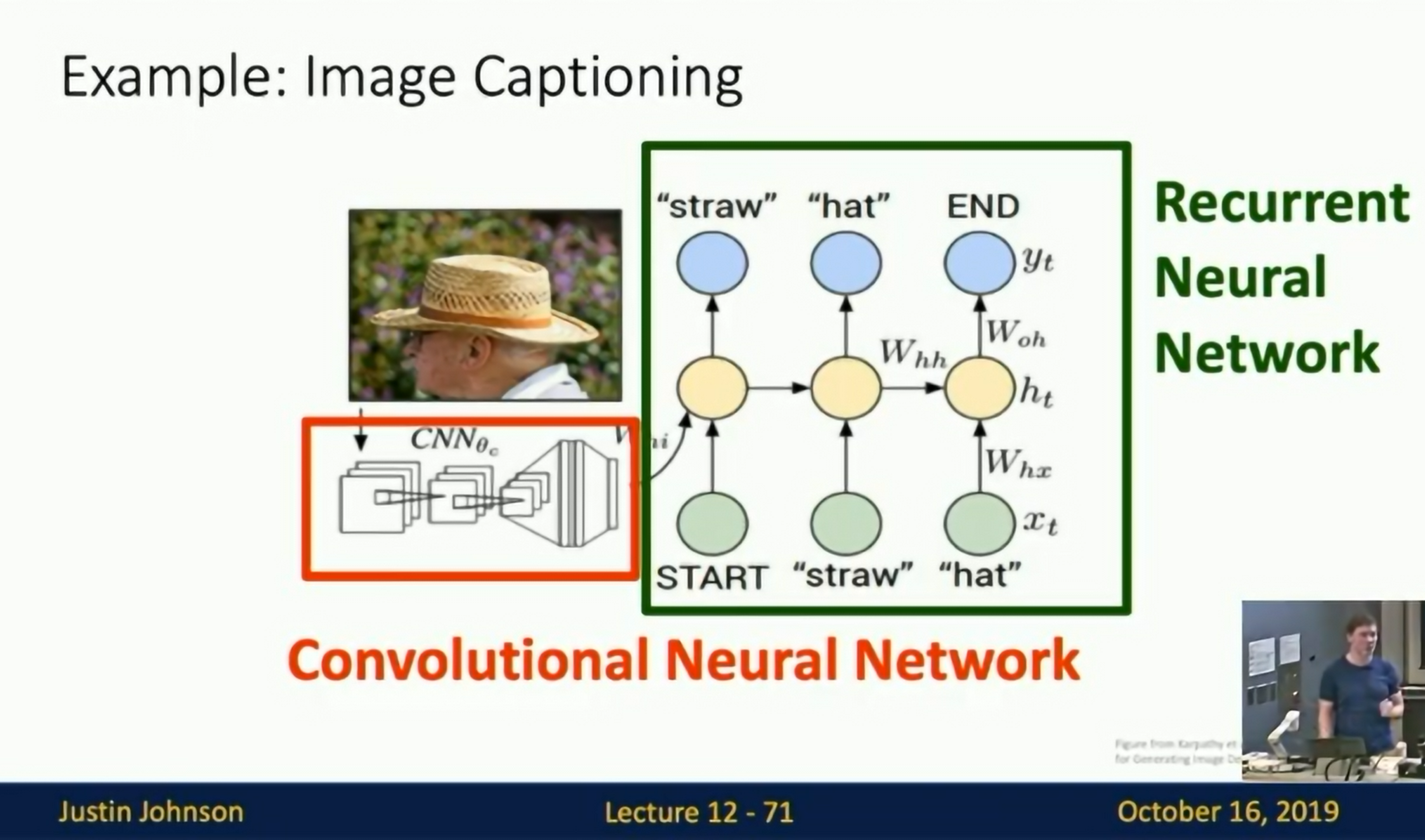
Image captioning
Transfer learning from CNN, then add RNN.
Results: arXiv:1411.4555
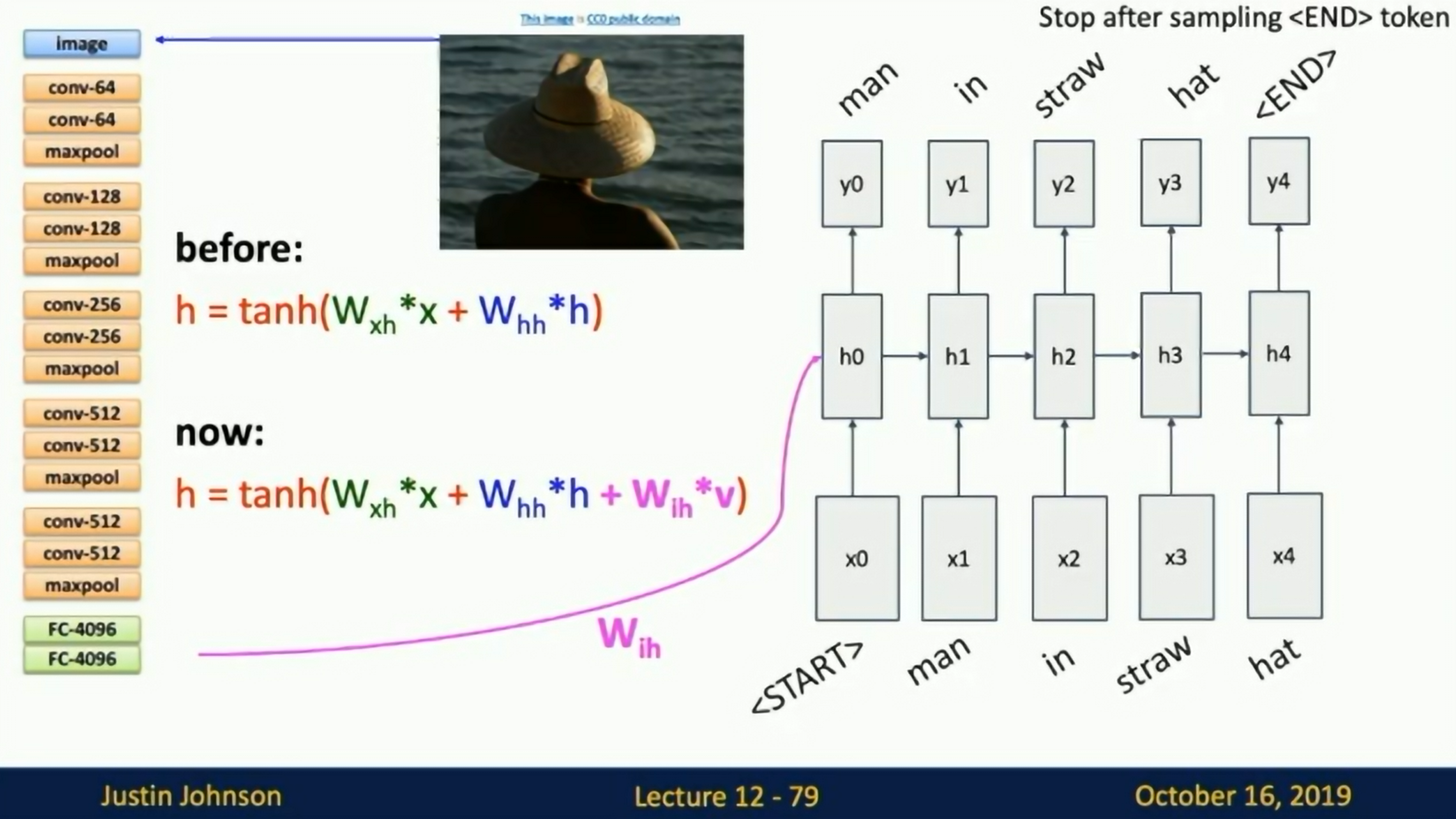
Image captioning results

Image captioning results
Failure Cases:

Failure Cases
Gradient Flow
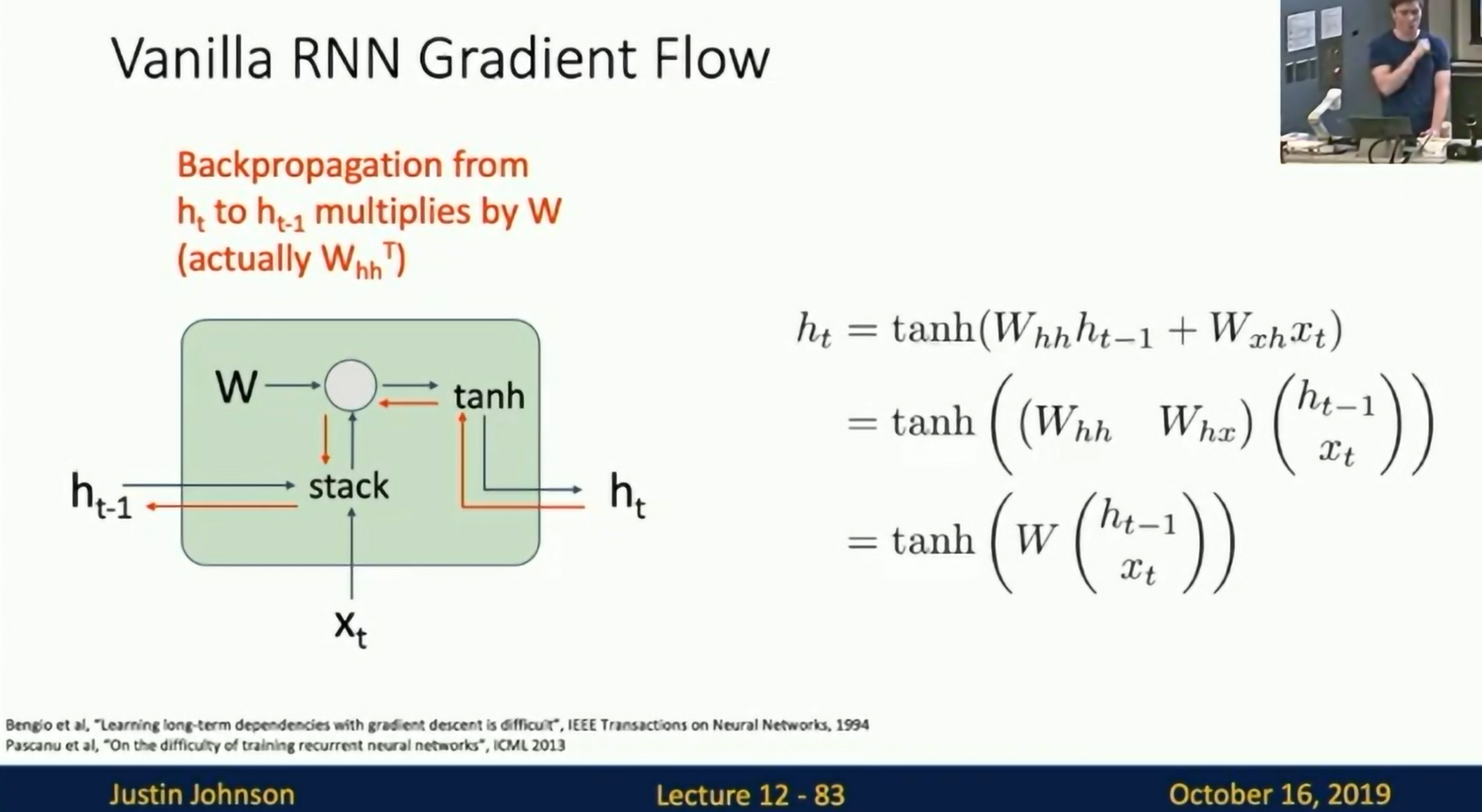
Gradient Flow
Computing gradient of involves many factors of W (and repeated tanh)
Gradient Clipping: Scale gradients if they get too large.
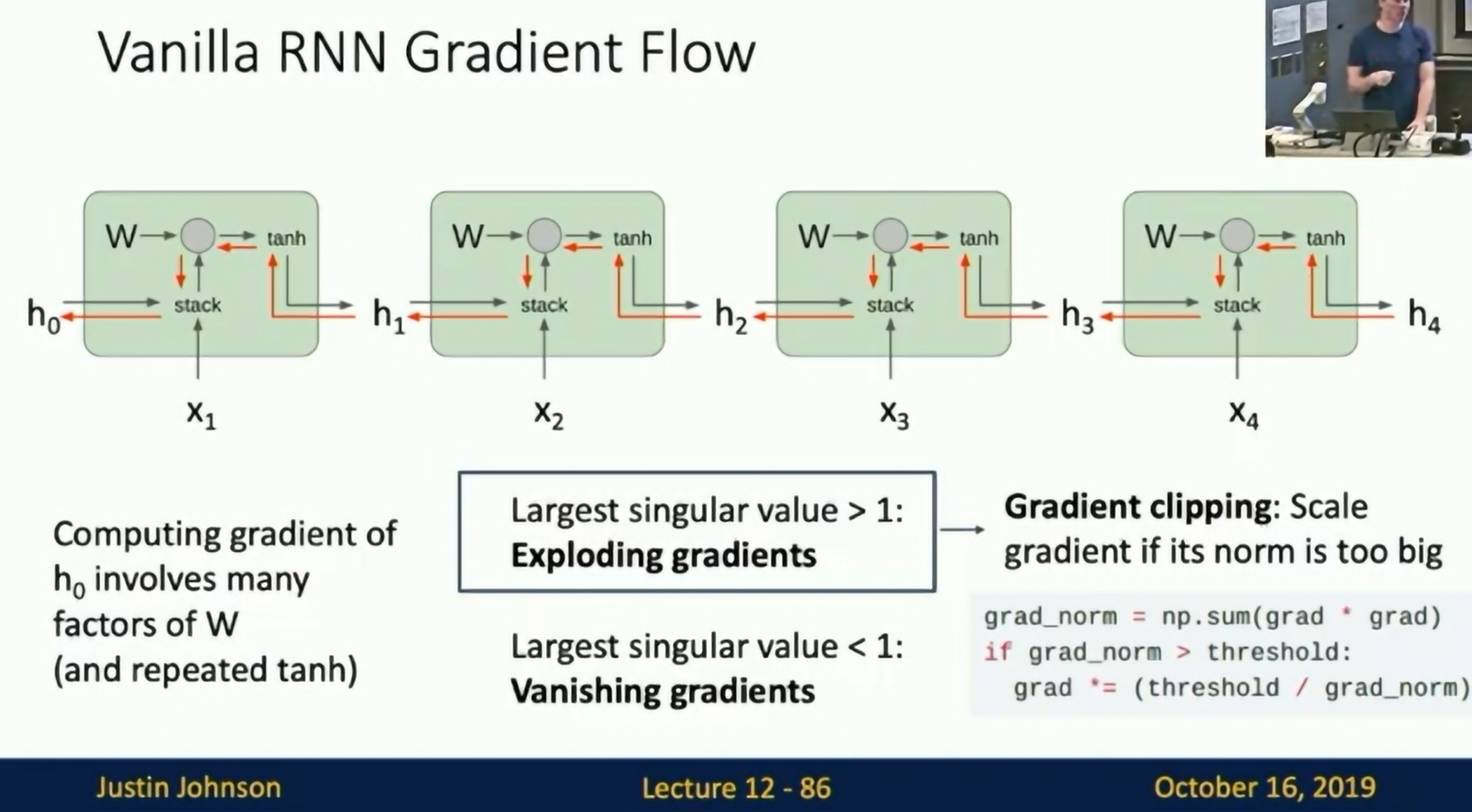
Gradient Clipping
Vanishing Gradient: If the gradient is too small, the weights won't change -> Change the architecture.
Long Short Term Memory (LSTM)

LSTM (1997)
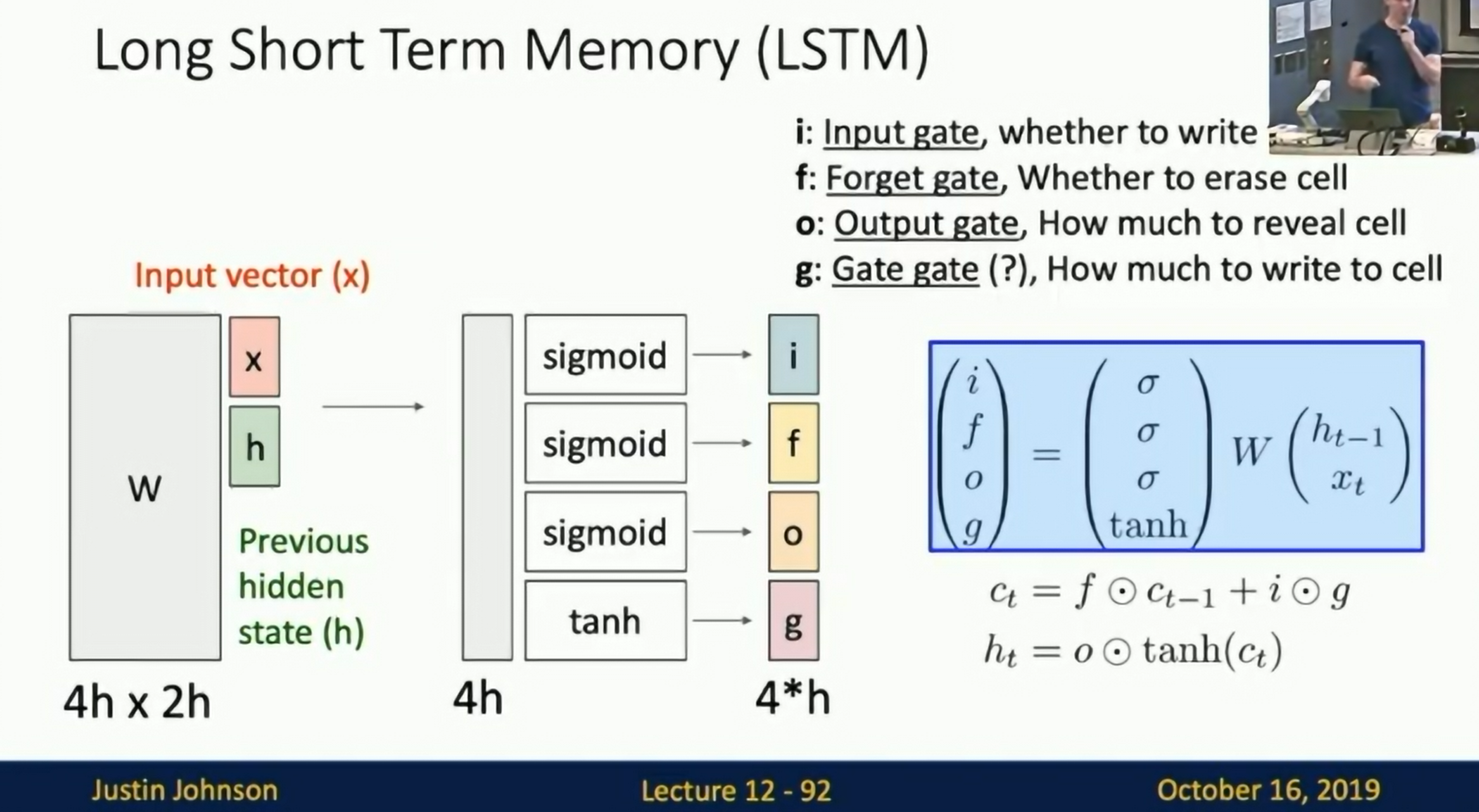
LSTM
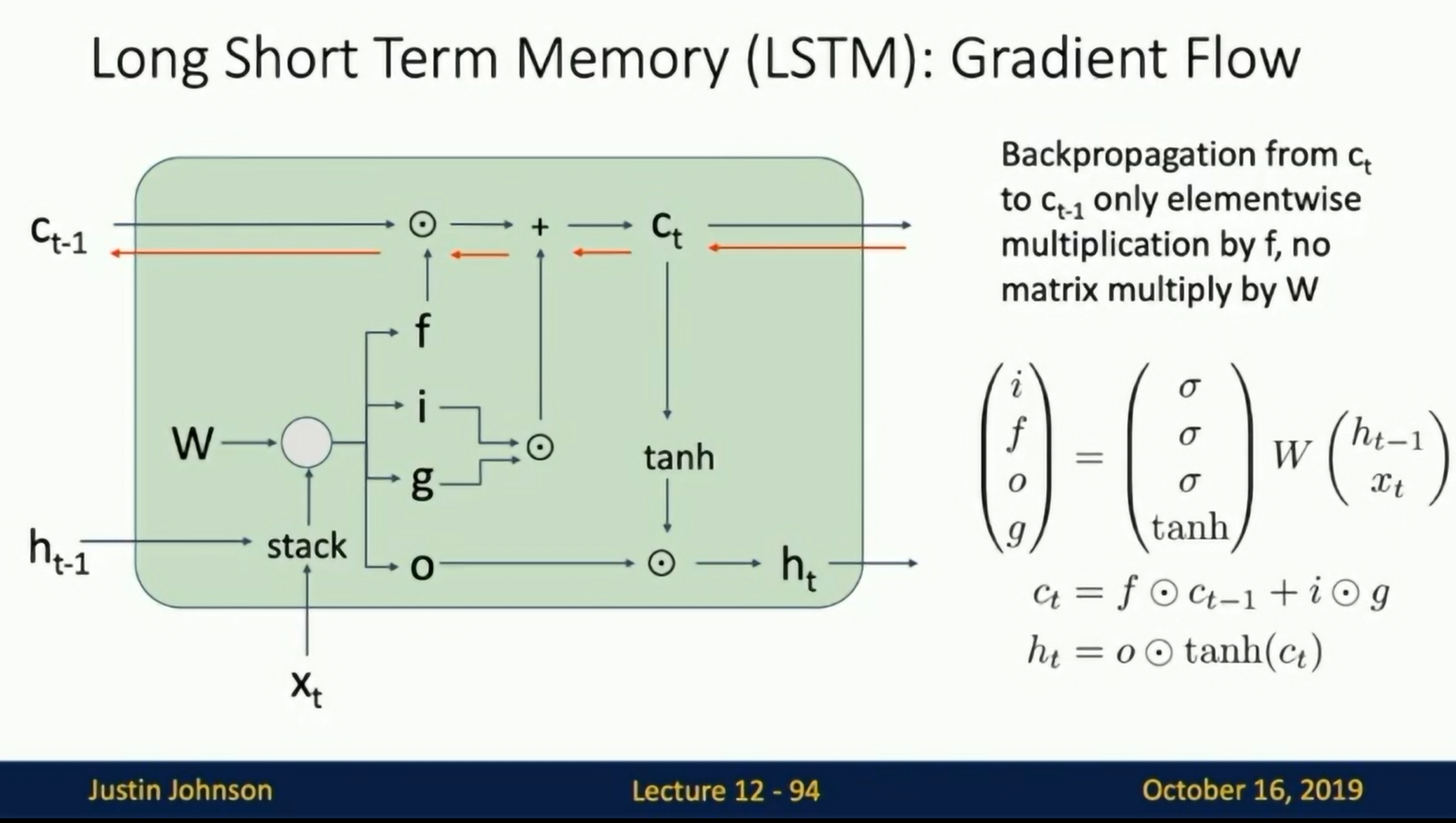
LSTM
Uninterrupted gradient flow!
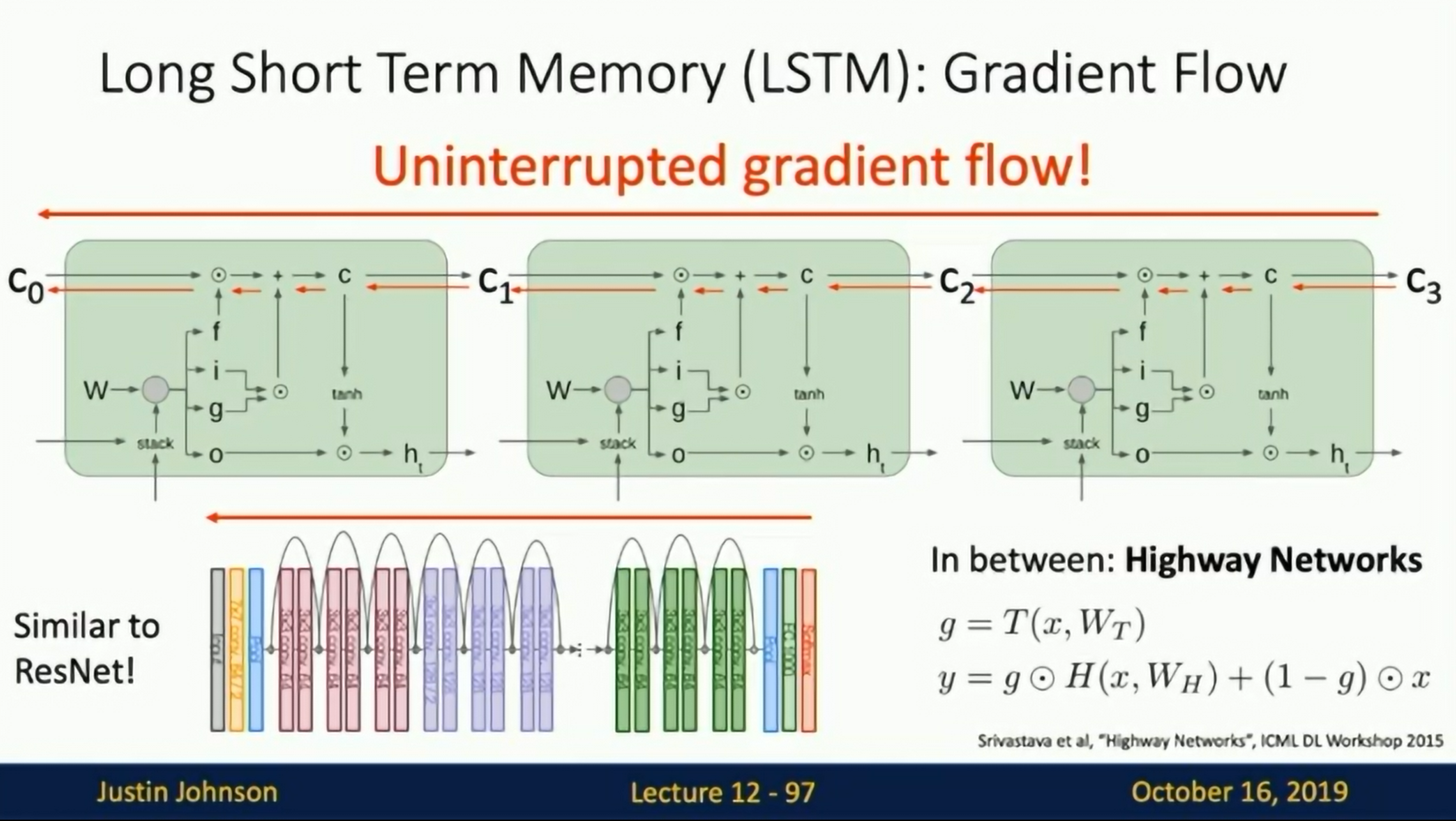
LSTM
Multi-layer RNNs

Two-layer RNN
Other RNN Variants

Search for RNN architectures empirically.
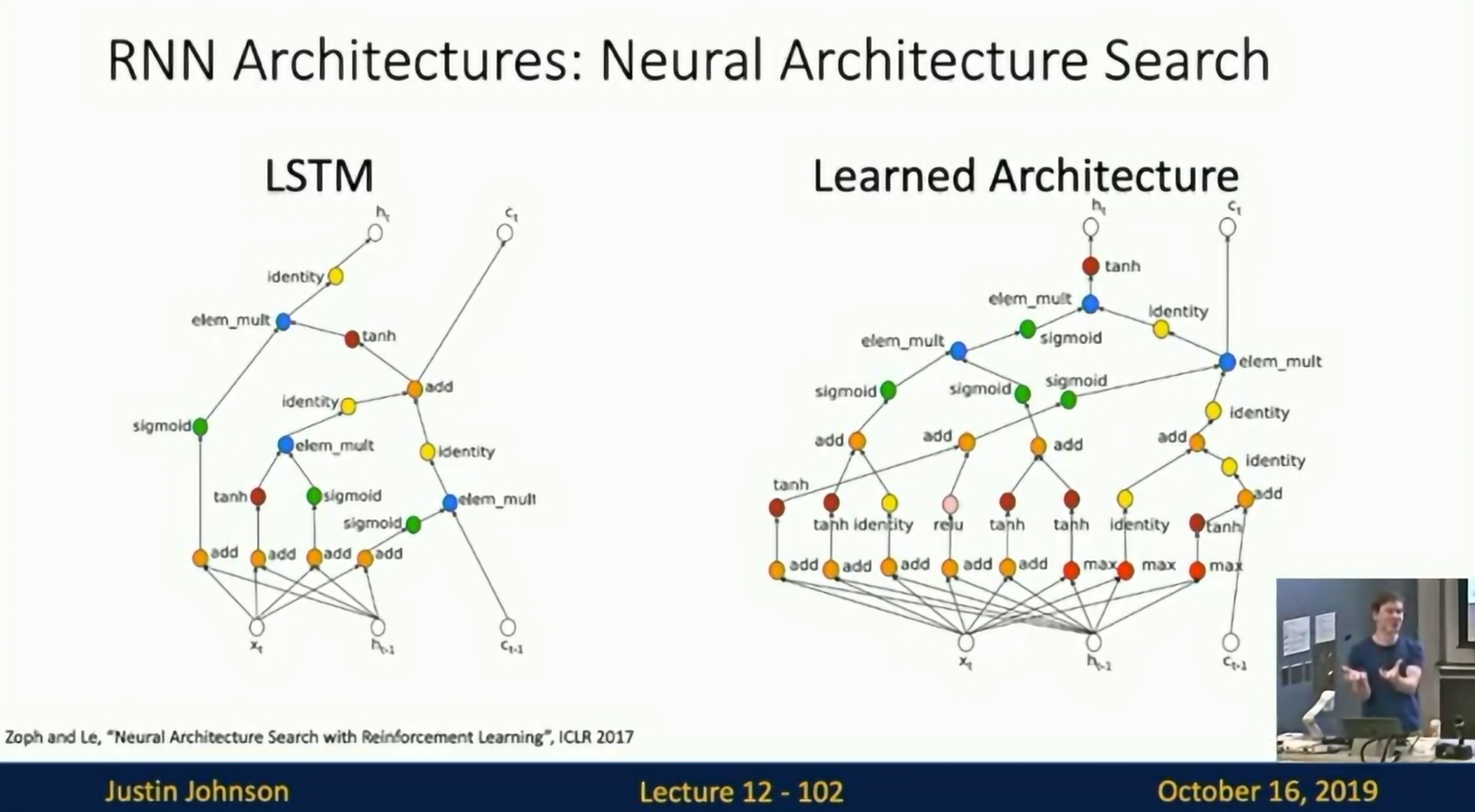
Neural Architecture Search.
Attention Mechanism
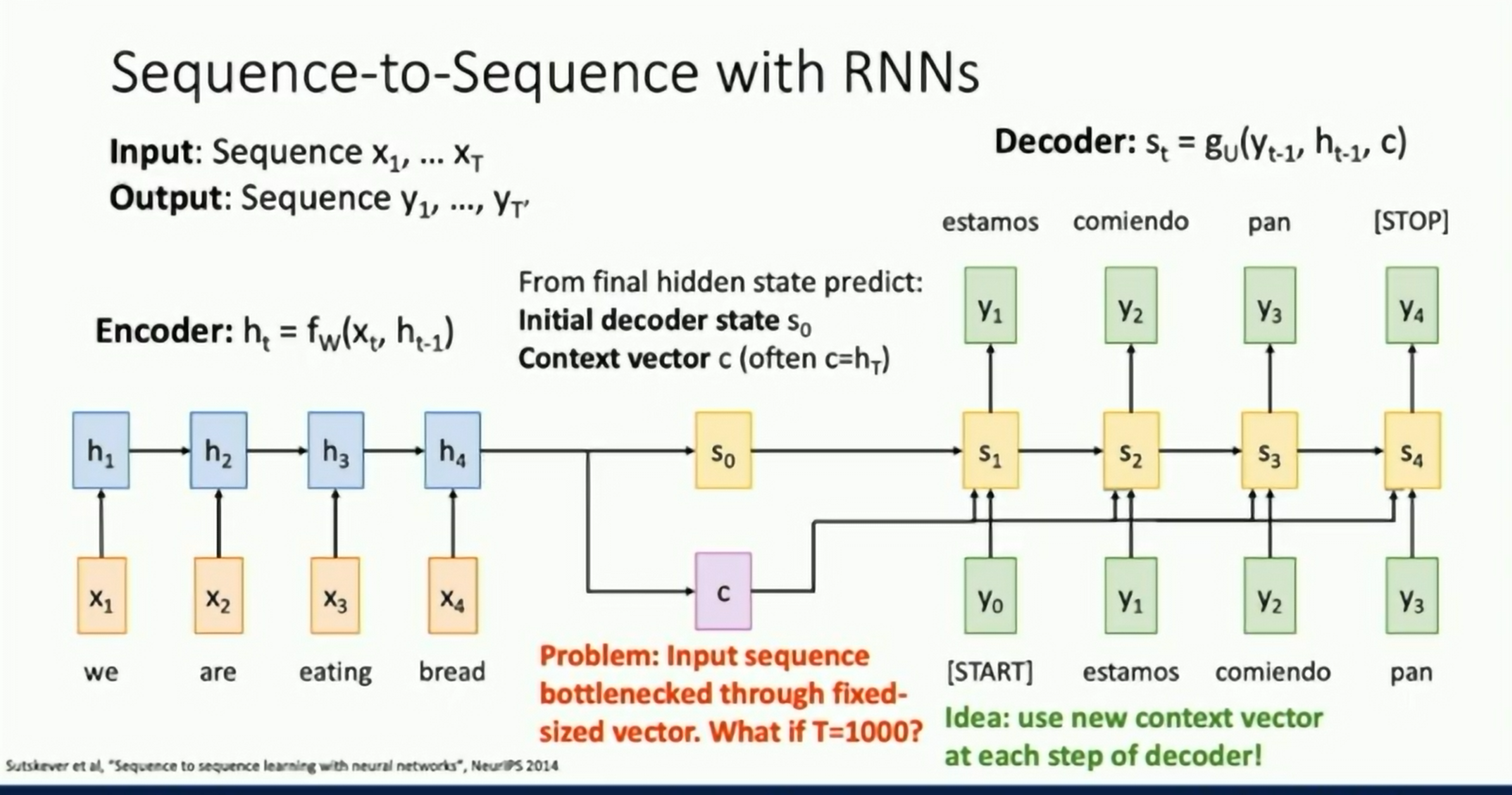
Problem of Attention: Long sequences are hard to process.
Attention Mechanism
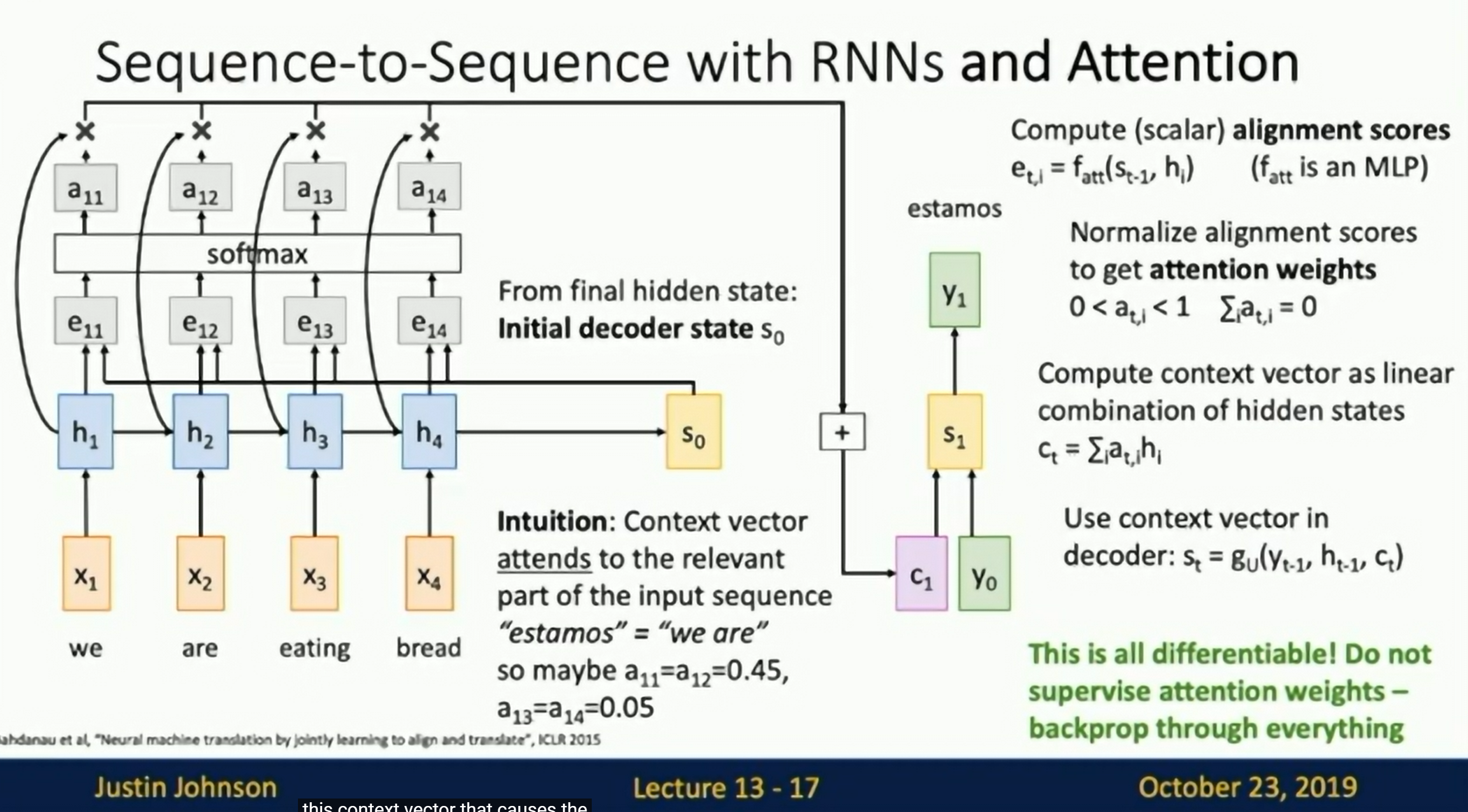
Seq to Seq with RNNs and Attention
Compute (scalar) alignment scores.
is an MLP
Normalize alignment scores to get attention weights ,
RNN
Compute context vector as weighted sum of encoder hidden states.
=
Use the context vector as input to the decoder:
Seq to Seq with RNNs and Attention
We do not need to tell the model to pay attention to which part of the input.
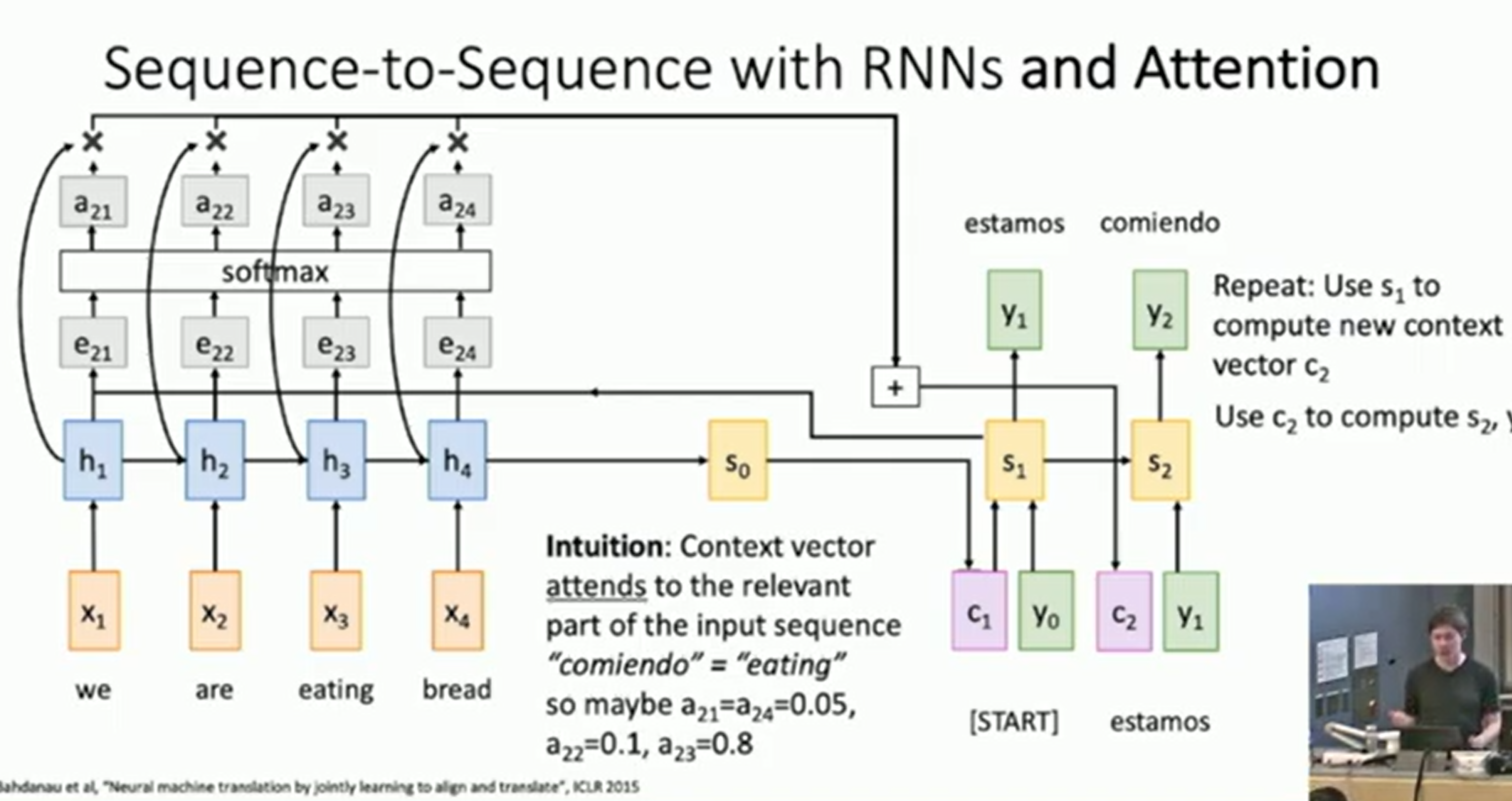
Seq to Seq with RNNs and Attention
Rather than trying to stuff all the information in a single vector, we give the model the ability to attend to different parts of the input.
Example: Translation Takes

Attention Matrix
Image Captioning with RNNs and Attention
CNN -> Attention to get Alignment Scores -> RNN
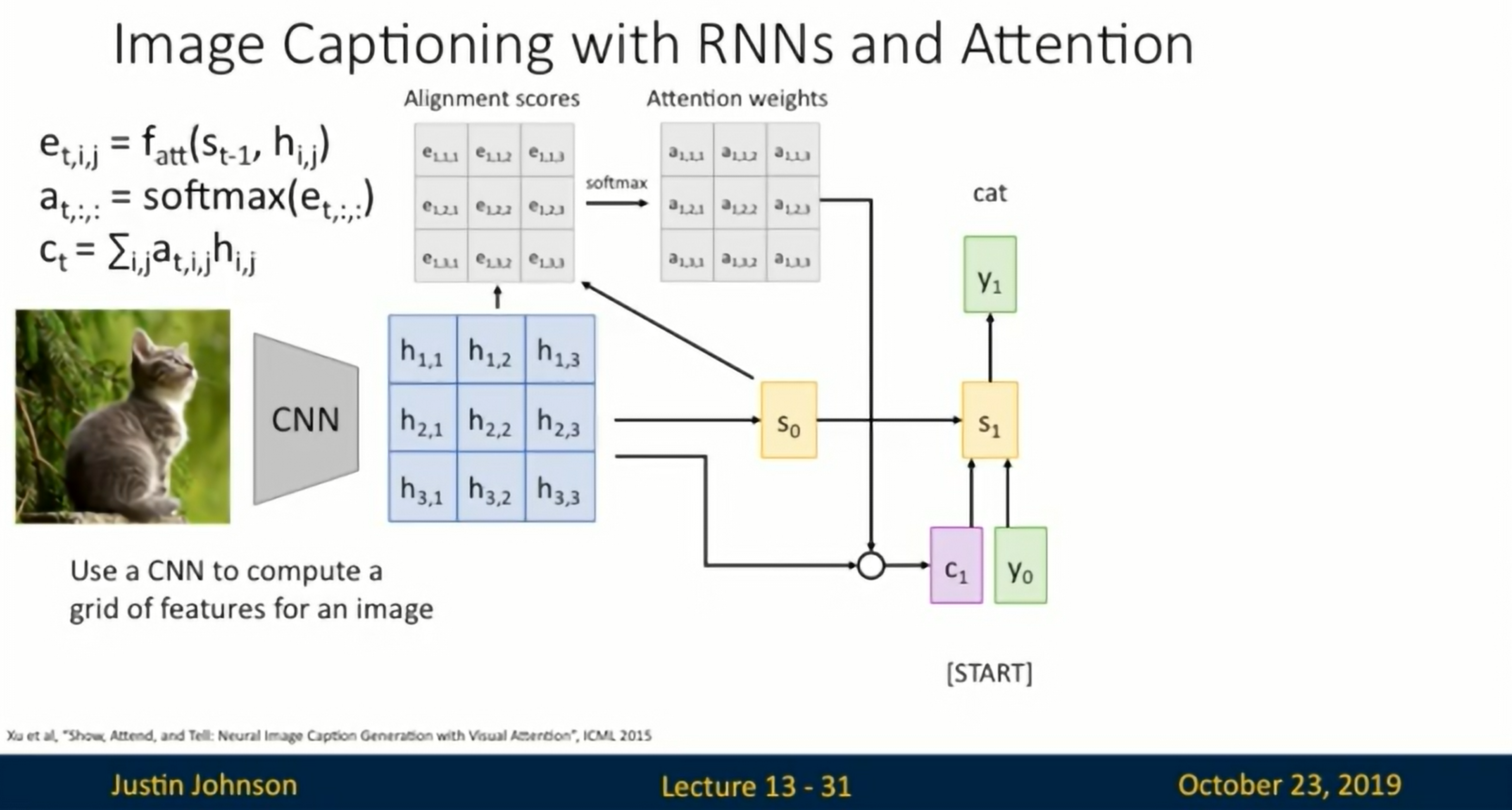
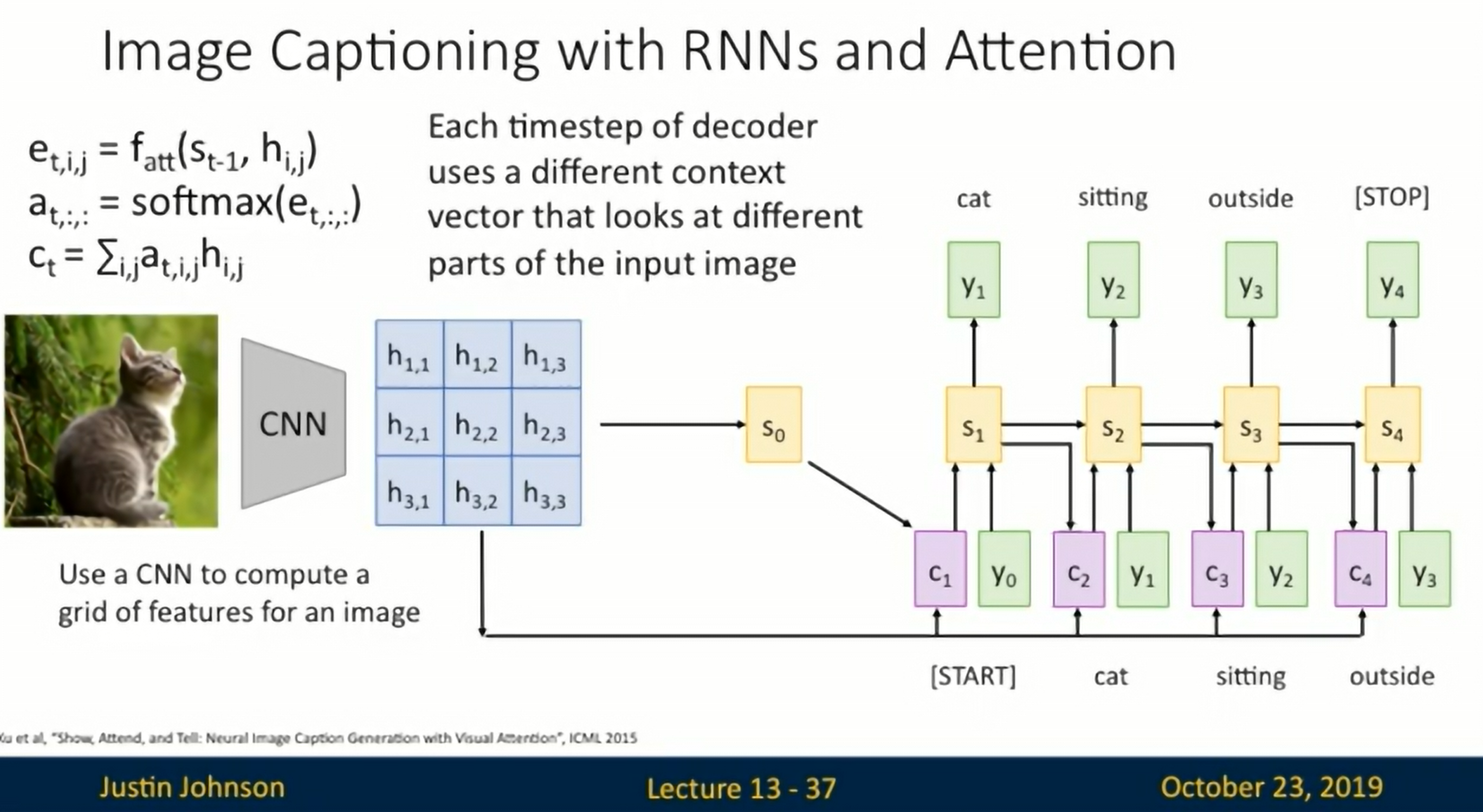
Image Captioning with RNNs and Attention
Neural Image Caption Generation with Visual Attention

Area to which the attention is attributed
Biological Inspiration
Our retina has a fovea, which is a high-resolution area in the center of our vision. Our eyes move around constantly to focus on different parts of the image so we don't notice.
Retina的中文是视网膜,Fovea是视网膜的中心区域,视网膜的中心区域是视觉最清晰的地 方,也是视觉最敏锐的地方。
X, attend, and Y
- Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
- Ask, Attend and Answer: Exploring Question-Guided Spatial Attention for Visual Question Answering
- Listen, Attend and Spell
- Listen, Attend and Walk
- Show, Attend, and Interact
- Show, Attend and Read
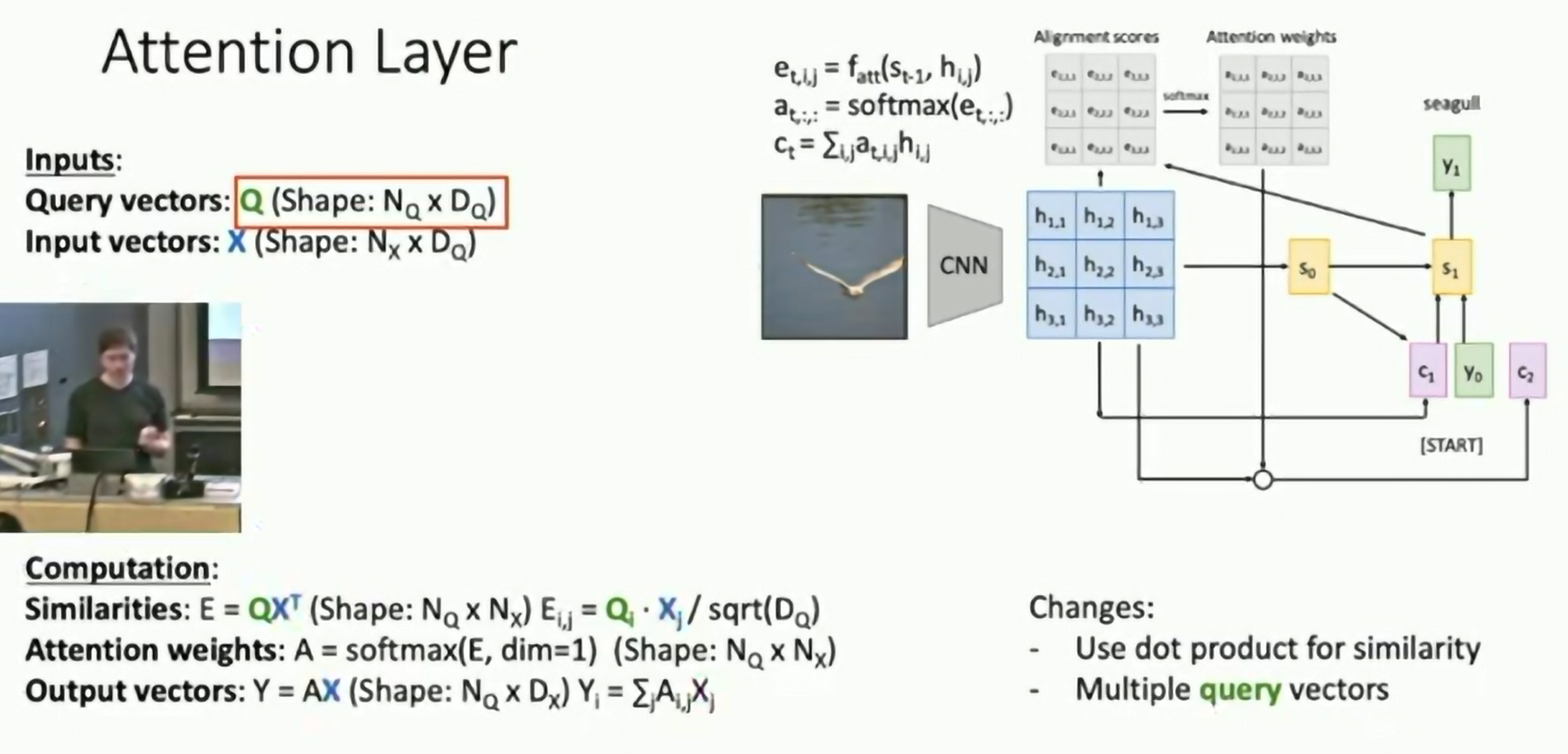
General-Purpose Attention Layer
Inputs: Query vector, Input vectors, and Similarity function. Computation: Similarities, Attention weights, Output vector.
1st generalization
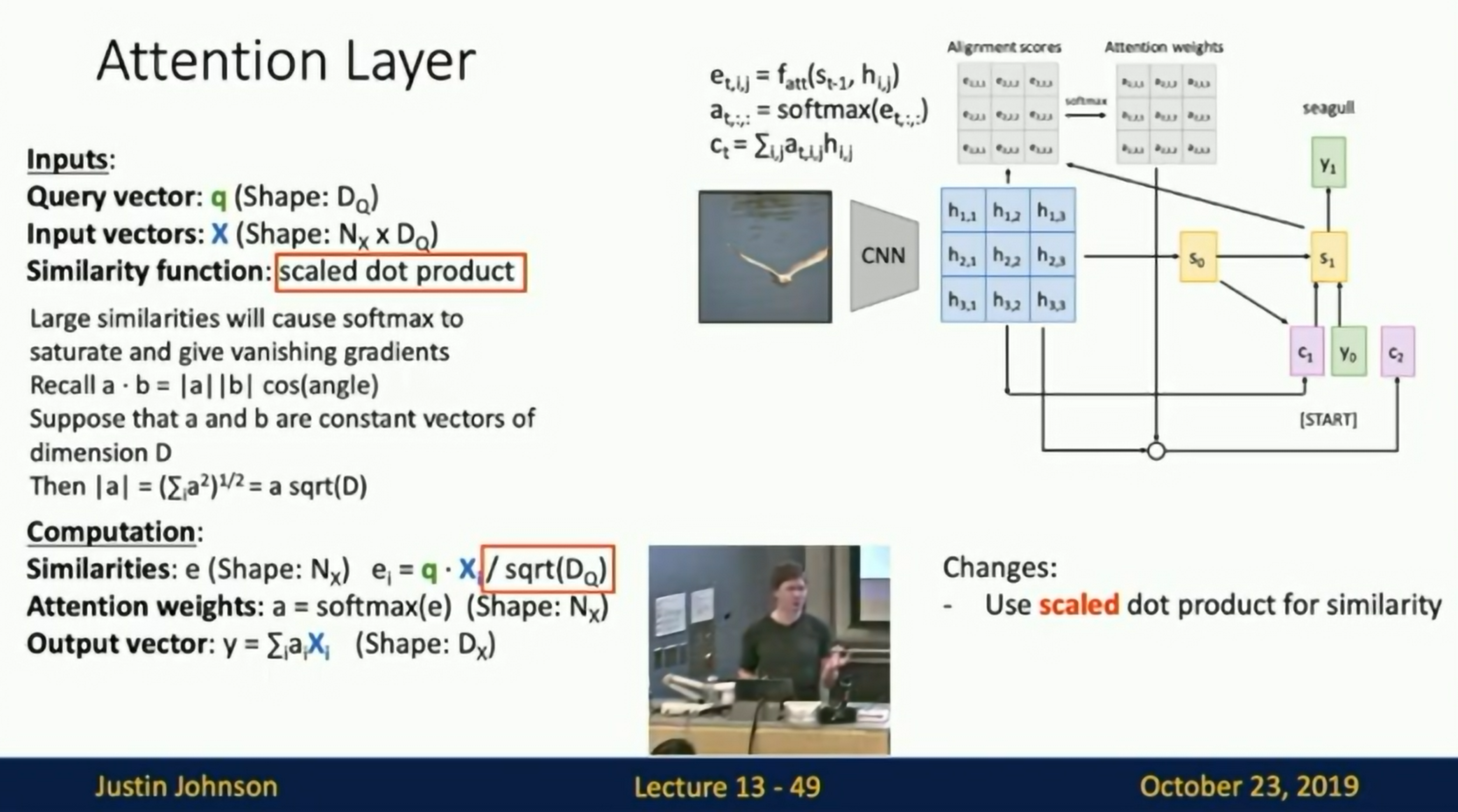
General-Purpose Attention Layer
Use scaled dot product for similarity
2nd generalization: Multiple query vectors
General-Purpose Attention Layer
3rd generalization: Query-Key-Value Attention

General-Purpose Attention Layer
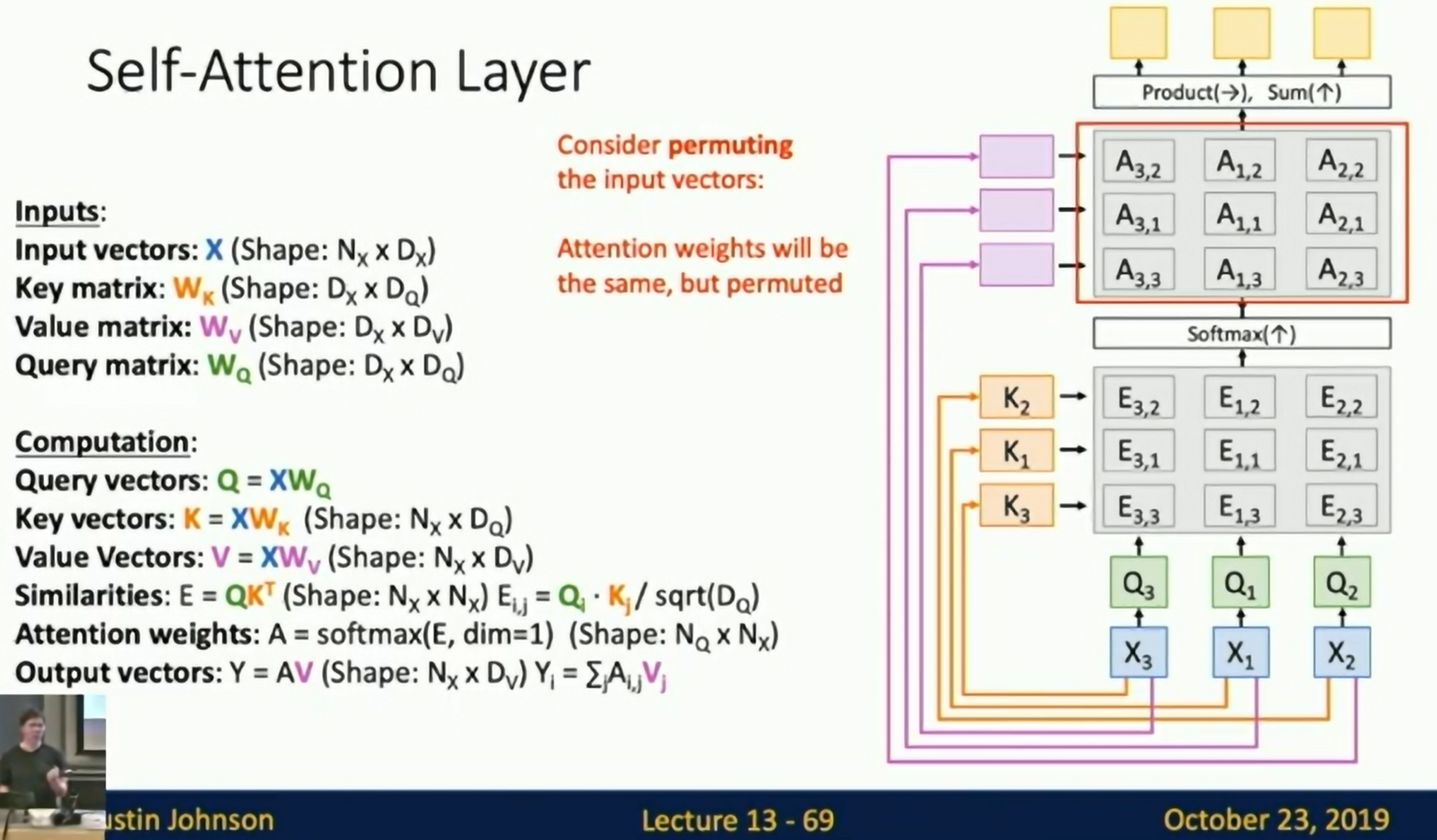
Self-Attention Layer
Self-Attention Layer
Problem: Self-attention is permutation invariant. It does not care about order all.
Solution: Positional encoding. We append a vector indicating the position of the word.

Self-Attention Layer
Masked Self-Attention
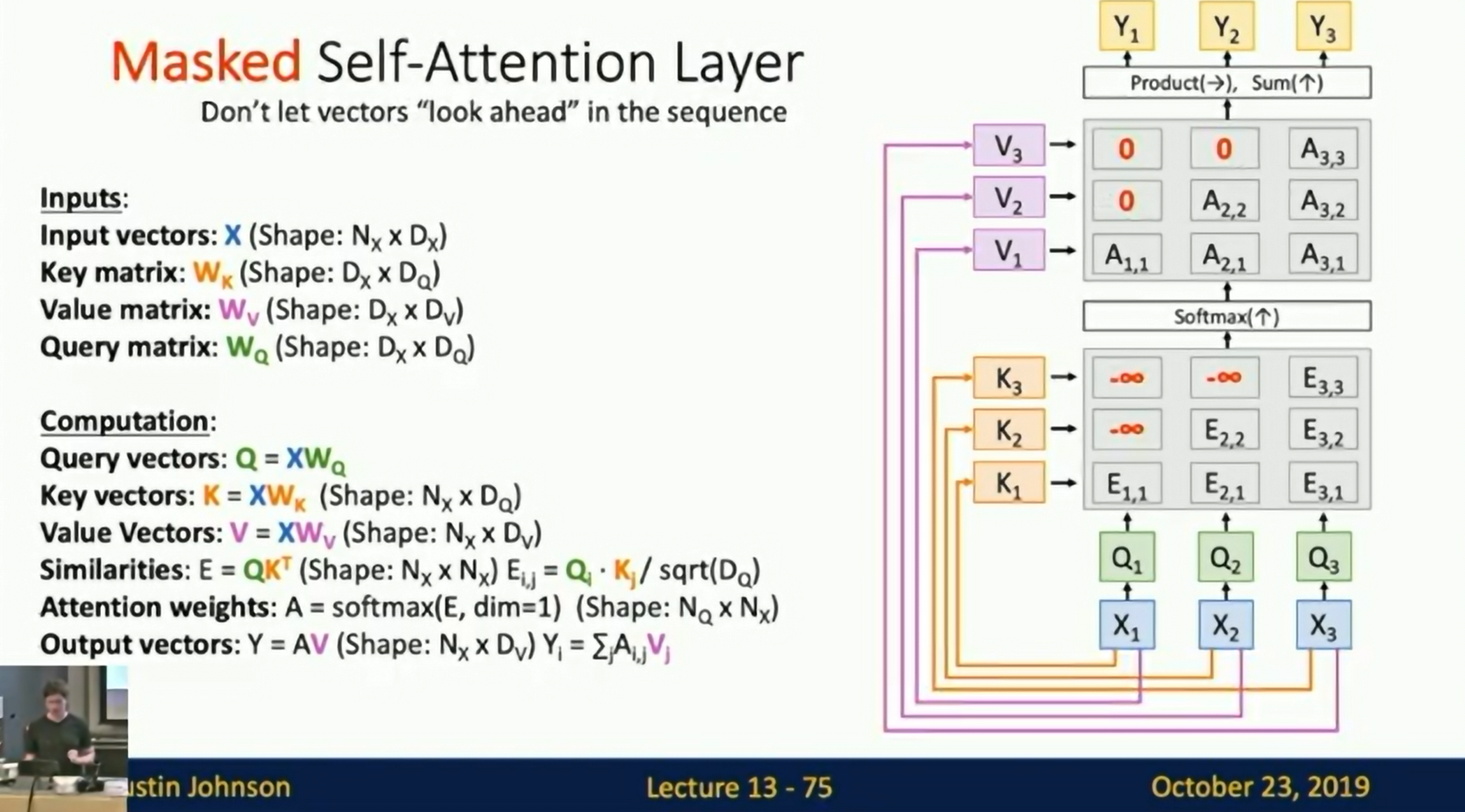
Masked Self-Attention
Multi-head Self-Attention

Multi-head Self-Attention
Example: CNN with Self-Attention
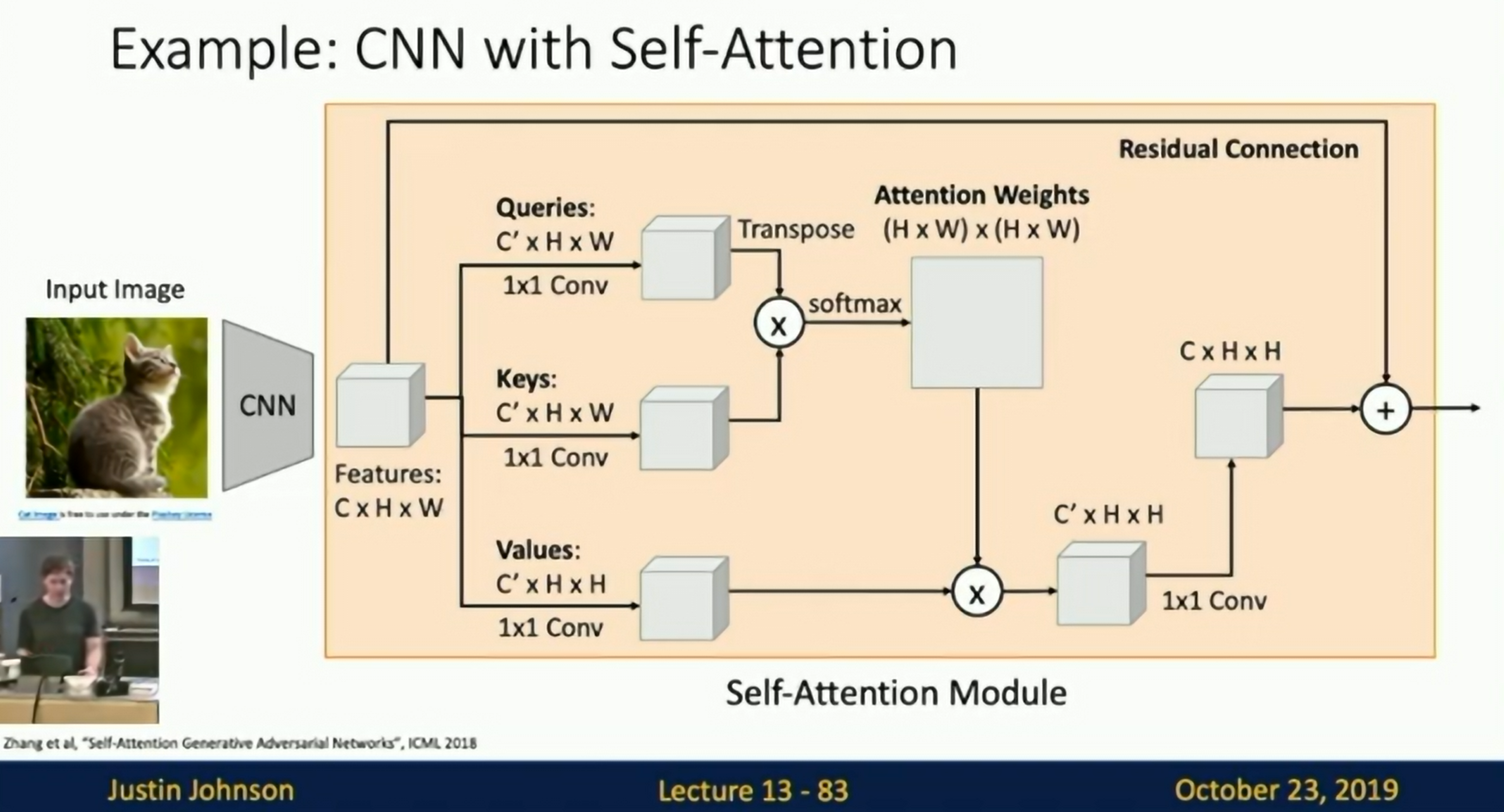
CNN with Self-Attention
Three ways of Processing Sequences
- RNN: works on ordered sequences, is good at long sequences: After one RNN layer, h_t sees the whole sequence. But it is not parallelizable.
- 1D Convolution: Works on Multidimensional Grids. It is not good at long sequences. It is highly parallelizable
- Self-Attention: Works on unordered sequences. It is good at long sequences. After one self-attention layer, each word sees the whole sequence. It is highly parallelizable. But memory complexity is quadratic in the sequence length.
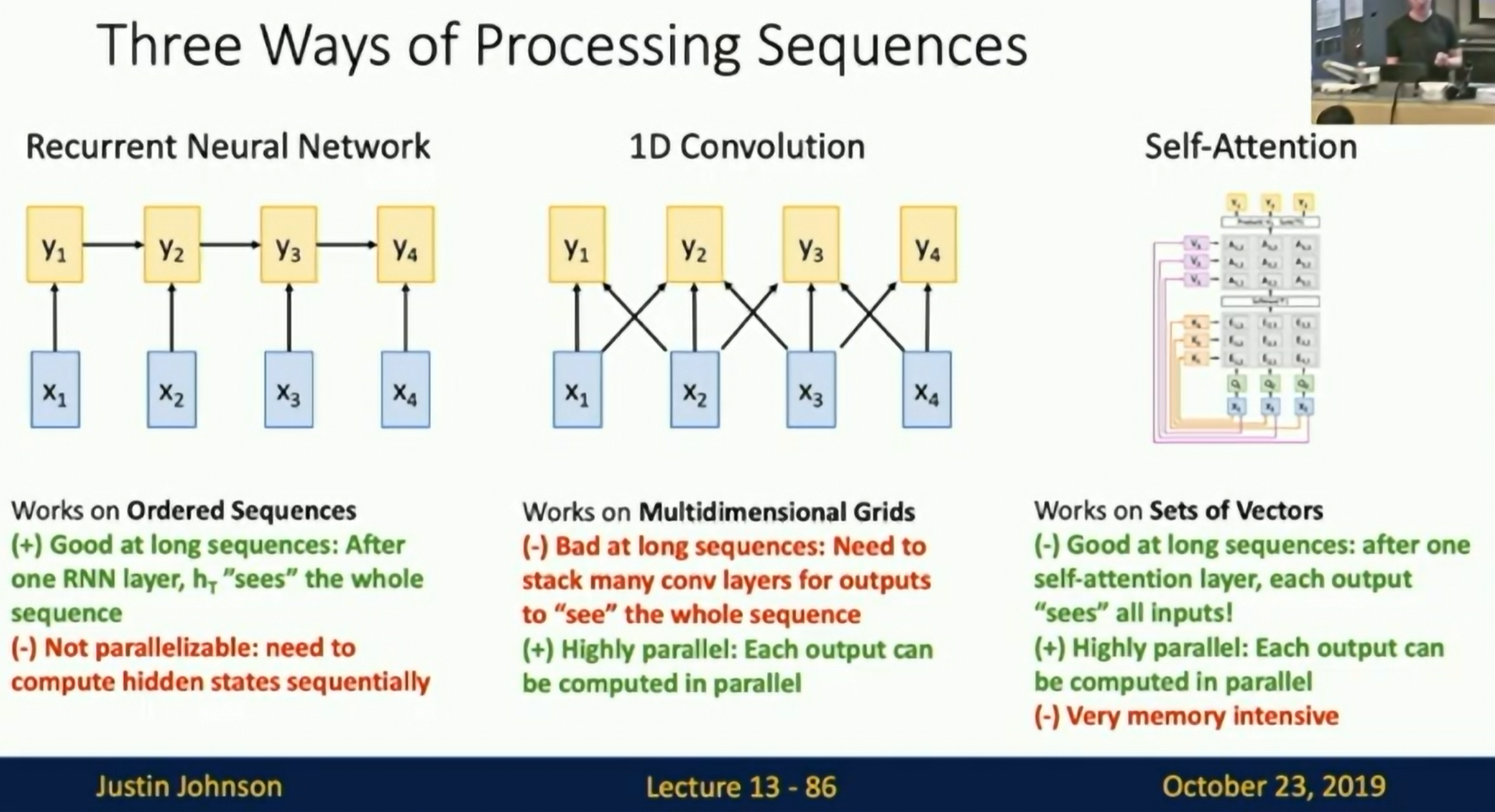
Three ways of Processing Sequences
Attention is All You Need
A model build only with self-attention layers.
Layer normalization: Self-attention is giving a set of vectors, and layer normalization does not add communication to the vectors.
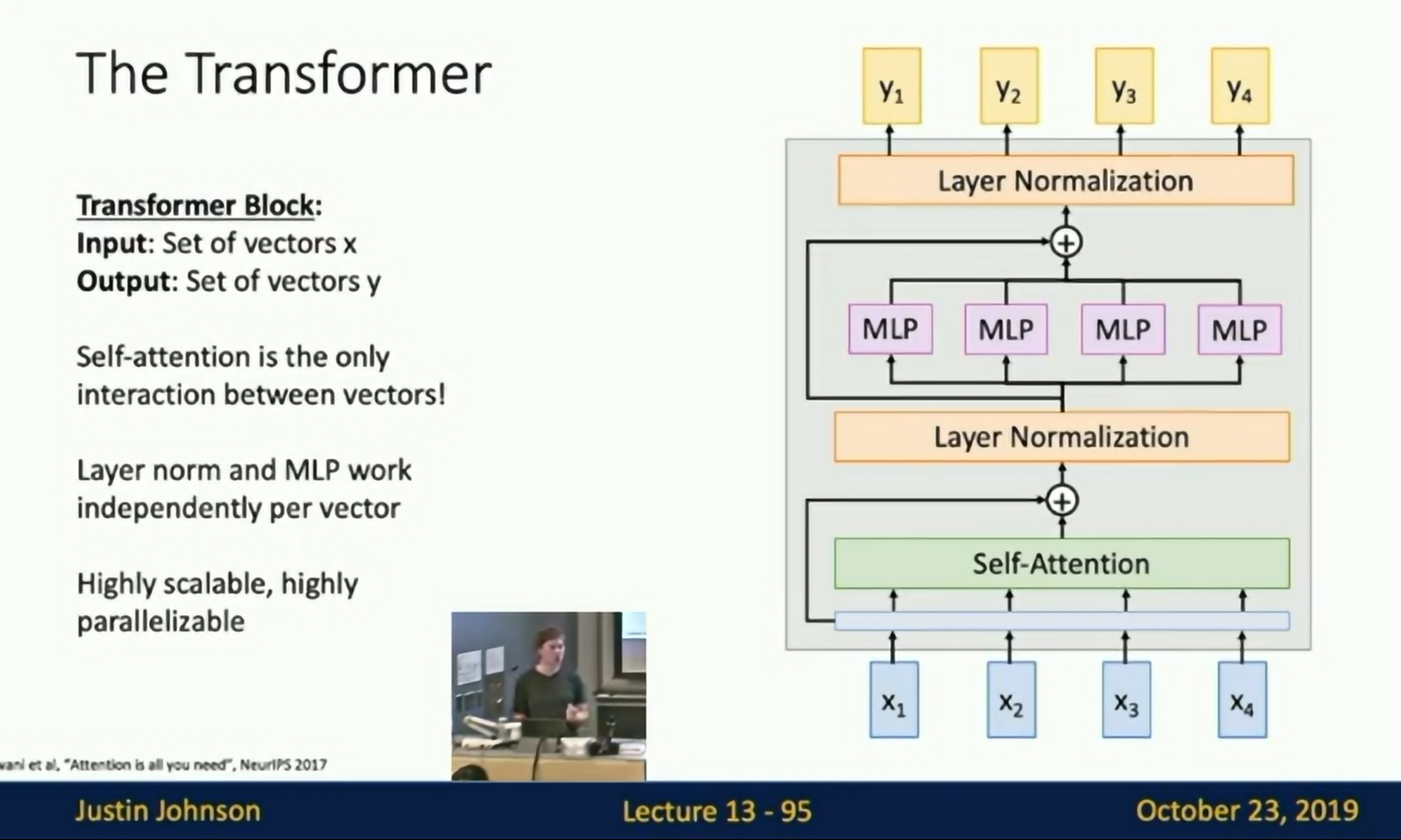
Attention is All You Need

The transformer
"ImageNet" Moment for Natural Language Processing.
Pretraining: Download a lot of text from the internet. Train a giant Transformer model for language modeling.
Fine-tuning: Fine-tune the transformer on your own NLP task.
Scaling up Transformers
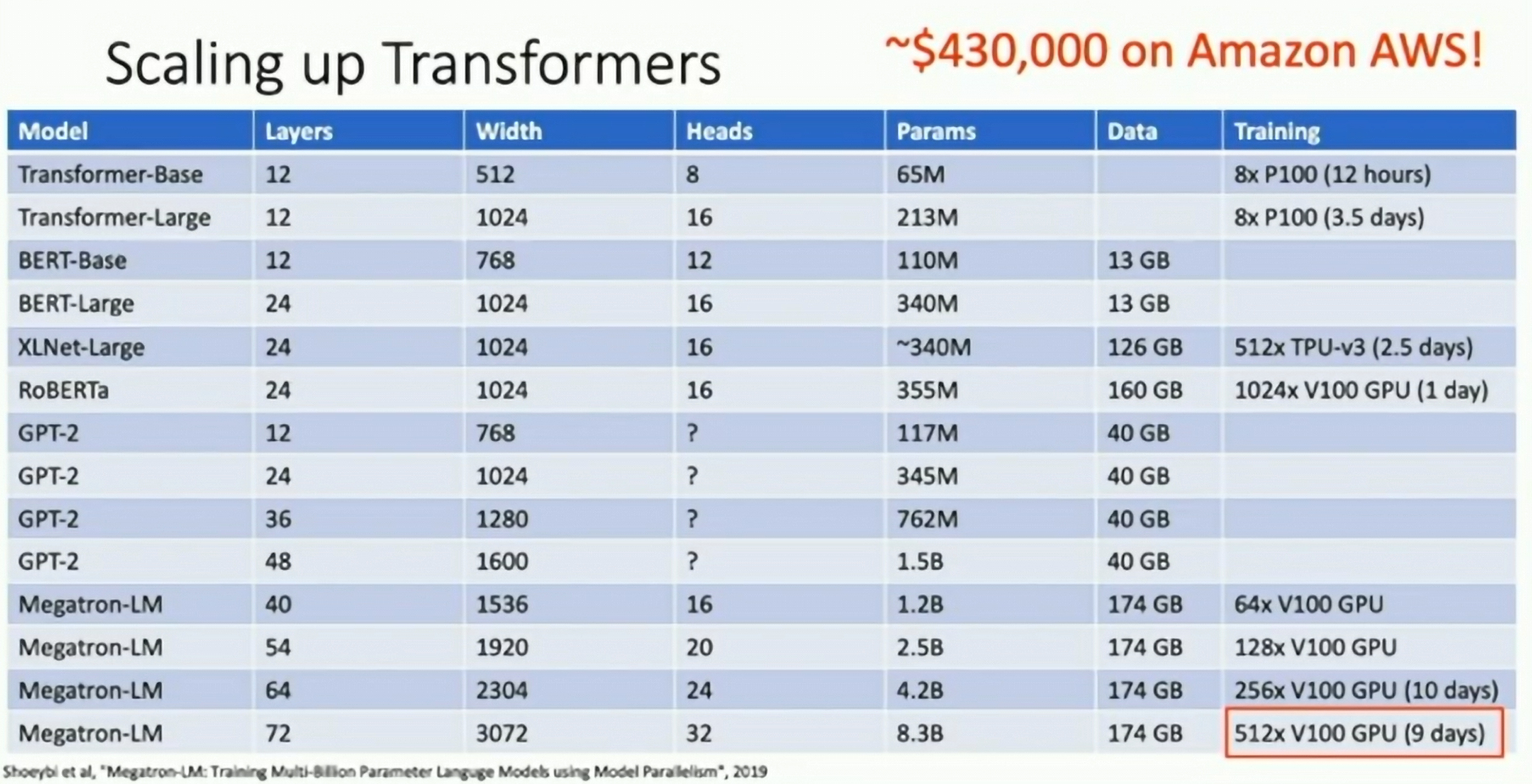
Scaling up Transformers
Summary
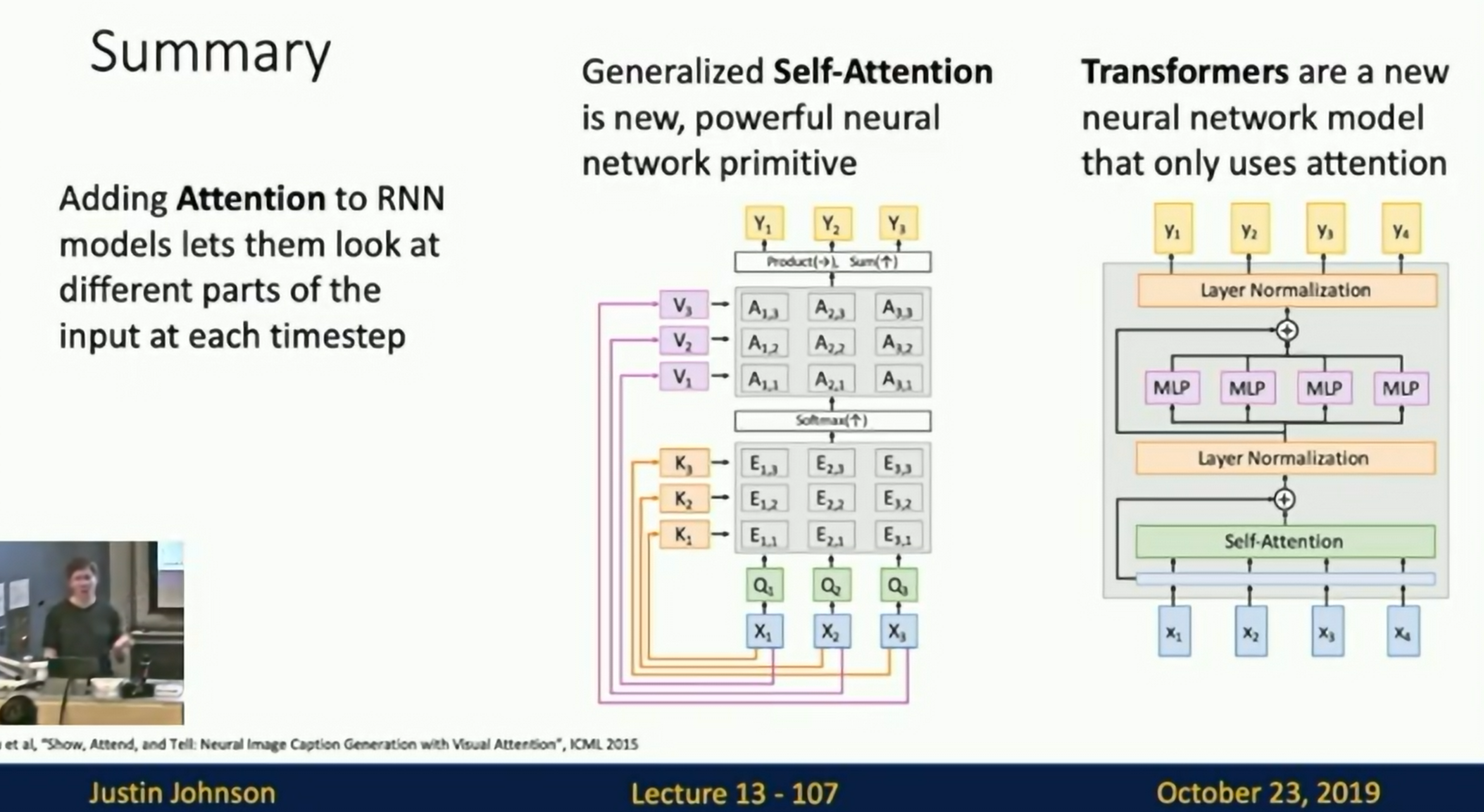
Summary
Notice on Usage and Attribution
This note is based on the University of Michigan's publicly available course EECS 498.008 / 598.008 and is intended solely for personal learning and academic discussion, with no commercial use.
- Nature of the Notes: These notes include extensive references and citations from course materials to ensure clarity and completeness. However, they are presented as personal interpretations and summaries, not as substitutes for the original course content.
- Original Course Resources: Please refer to the official University of Michigan website for complete and accurate course materials.
- Third-Party Open Access Content: This note may reference Open Access (OA) papers or resources cited within the course materials. These materials are used under their original Open Access licenses (e.g., CC BY, CC BY-SA).
- Proper Attribution: Every referenced OA resource is appropriately cited, including the author, publication title, source link, and license type.
- Copyright Notice: All rights to third-party content remain with their respective authors or publishers.
- Content Removal: If you believe any content infringes on your copyright, please contact me, and I will promptly remove the content in question.
Thanks to the University of Michigan and the contributors to the course for their openness and dedication to accessible education.