UM-CV 15 Object Detection
Summary
Slow R-CNN, Fast R-CNN, Faster R-CNN, Single-Stage Object Detection, and their comparison.
@Credits: EECS 498.007 | Video Lecture: UM-CV 5 Neural Networks
Personal work for the assignments of the course: github repo.
Notice on Usage and Attribution
These are personal class notes based on the University of Michigan EECS 498.008 / 598.008 course. They are intended solely for personal learning and academic discussion, with no commercial use.
For detailed information, please refer to the complete notice at the end of this document
Intro
Task Definition
Input: Single RGB image Output: A set of detected objects; for each object predict:
Computer Vision Tasks:Classification, Semantic Segmentation, Object Detection, Instance Segmentation
- Category label (from fixed, known set of categories)
- Bounding box (four numbers, x, y, width, height)
Challenges
- Multiple outputs: Need to output variable numbers of objects per image
- Multiple types of output" Need to predict "what" (category label) as well as "where" (bounding box)
- Large images: Classification works at 224 x 224; need higher resolution for detection, often 800 x 800 or more
- Detecting Multiple Objects: Need different numbers of outputs per image
Region-based CNN (R-CNN)
CVPR 2014
Window Detection
Sliding Window?
Apply a cnn to many different crops of the image, CNN classifies each crop as object or background. And enumerate all possible crops -> too slow.
Region Proposals: Find a small set of boxes that are likely to cover all objects. Often based on heuristics: e.g. look for "blob-like" image regions. This is relatively fast to run; e.g. Selective Search gives 2000 region proposals in a few seconds on CPU
Regions of interest (RoI) from a proposal methods. For each RoI, apply a CNN to predict the class of the object in the RoI and refine the bounding box.
Bounding box regression: predict "transform" to correct the RoI: x, y, w, h
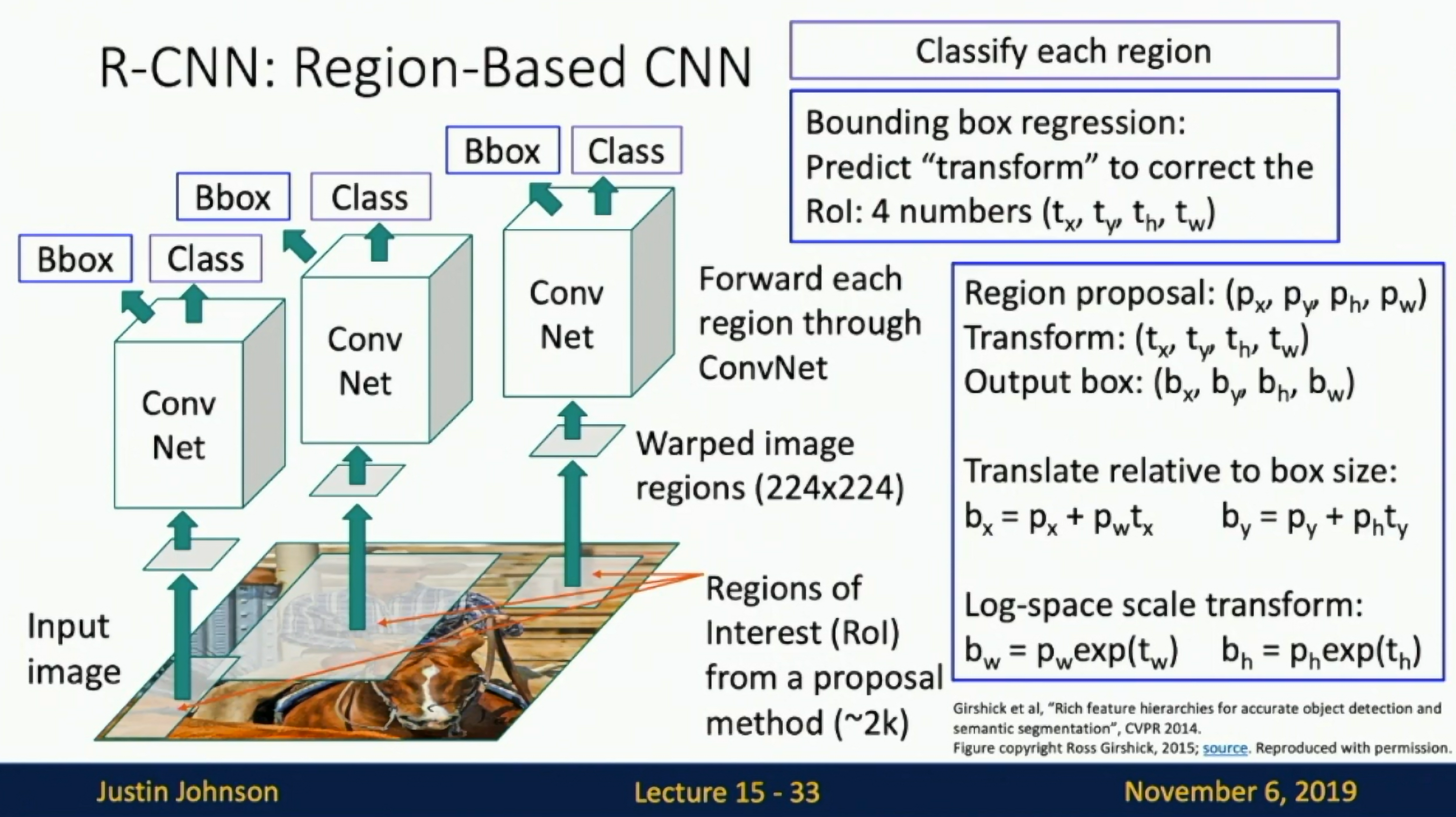
Fig: Bounding-box regression

Fig: R-CNN
During training, backpropagate on all the regions of interest (RoIs).
Comparing Boxes: Intersection over Union (IoU)
- IoU = Area of overlap / Area of union. Also called "Jaccard similarity" or "Jaccard index".
- IoU > 0.5 is "decent". IoU > 0.7 is "good". IoU > 0.9 is "almost perfect".
Overlapping Boxes
Object detectors often output many overlapping detections. Solution: Post-process raw detections using Non-Max Suppression (NMS).
- Select next highest-scoring box
- Eliminate lower-scoring boxes with IoU > threshold

Fig: Non-Max Suppression
Problem: NMS may eliminate "good" boxes when objects are highly overlapping...
Evaluating Object Detectors: Mean Average Precision (mAP)
- Run object detector on all test images (with NMS)
- For each category, compute average precision (AP) = area under precision vs recall curve

Fig: Mean Average Precision
- mean Average Precision (mAP) = mean of AP over all categories
- for "COCO mAP", average over 10 IoU thresholds (0.5 to 0.95) and take average

Fig: COCO mAP
Fast-RCNN
ICCV 2015
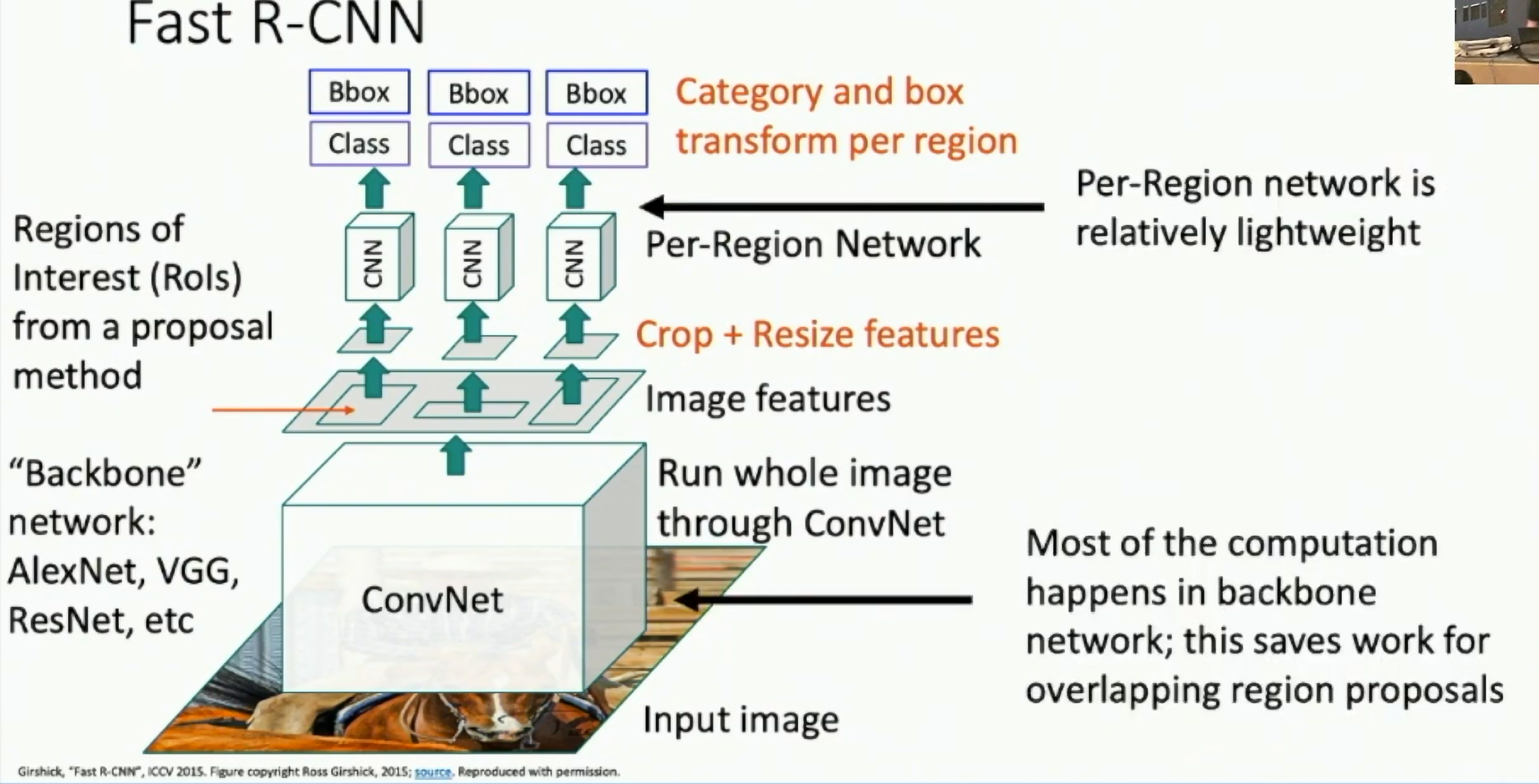
Fig: Fast-RCNN
Crop Features: RoI Pool
Input Image: e.g. 3 x 640 x 480 -> CNN (e.g. 512 x 20 x15)
Project and snap RoI to CNN feature map - > Divide into 2x2 grid of (roughly) equal subregions -> Max pool within each subregion (e.g. 512 x 7 x 7)
Region features always the same size even if input regions have different sizes!
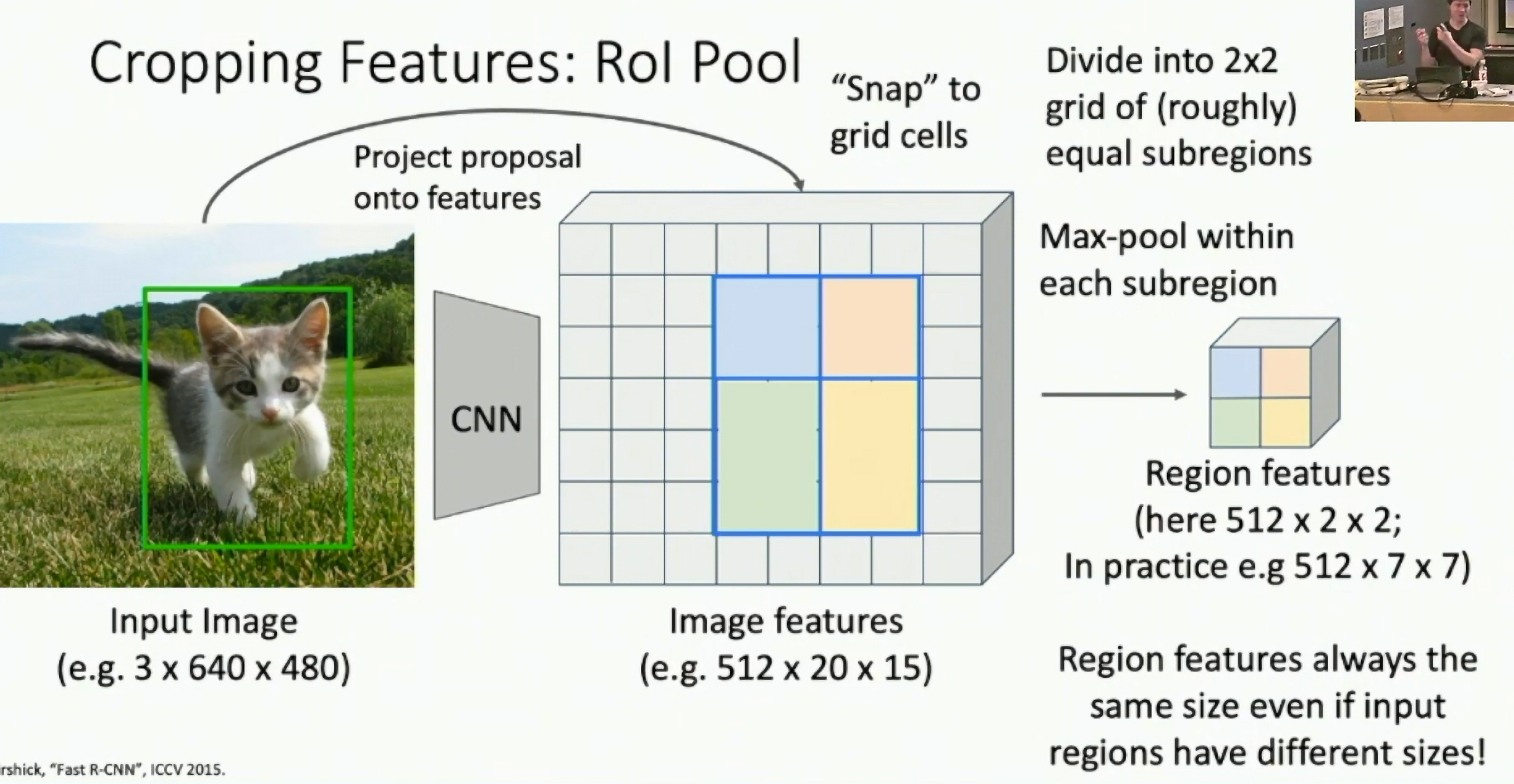
Fig: RoI Pool
Problem: Slight misalignment between RoI and CNN grid can cause misalignment in RoI Pooling. Solution: RoI Align
RoI Align
- Instead of snapping RoI to CNN grid, interpolate between grid points
- More accurate, but more expensive
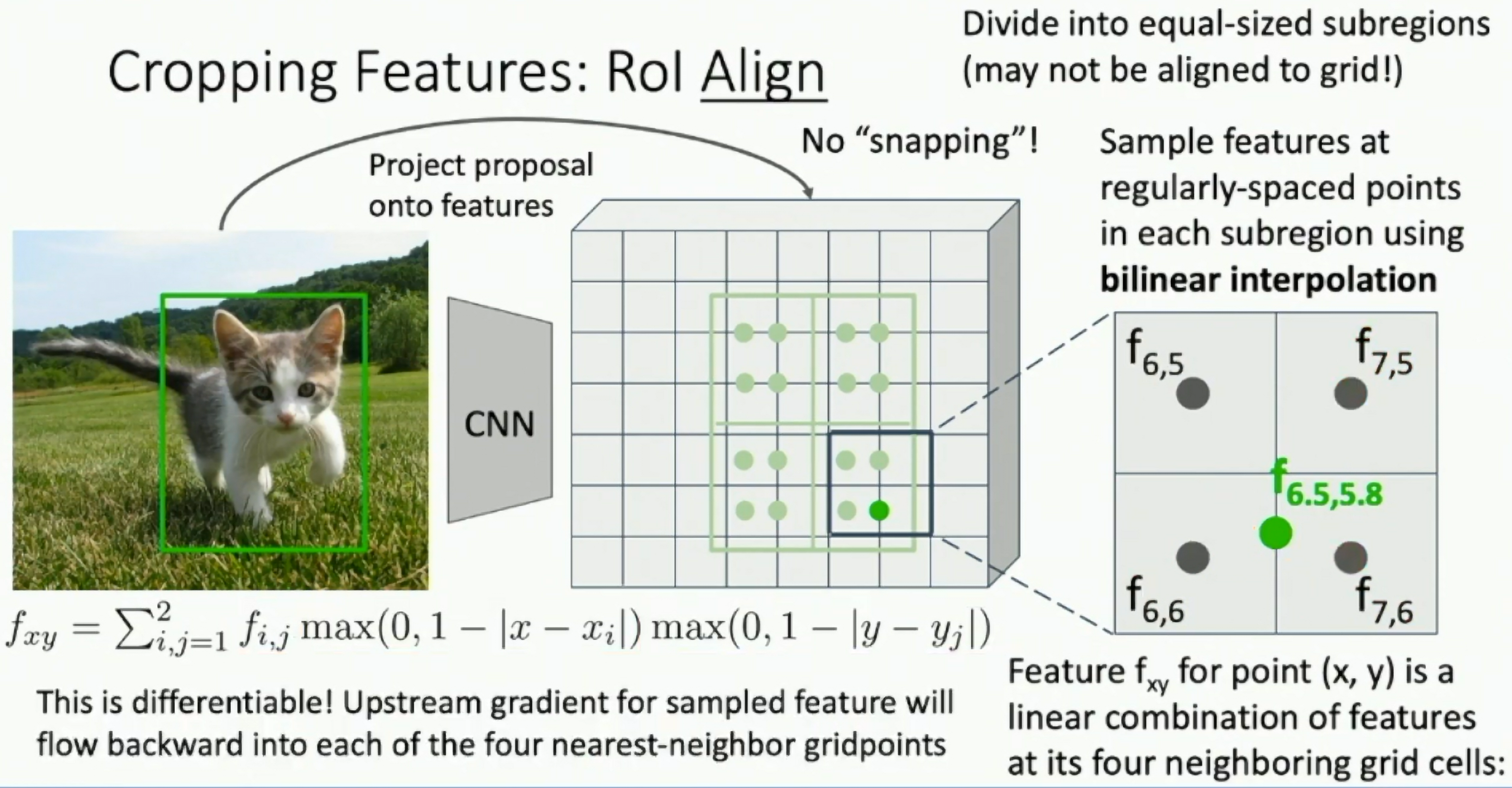
Fig: RoI Align
The cropping may not perfectly match the original object grid. RoI Align implements a bilinear near-neighbor interpolation to get more accurate cropping. We can consider the image as a real-valued tensor and backpropagate to any points in the image.
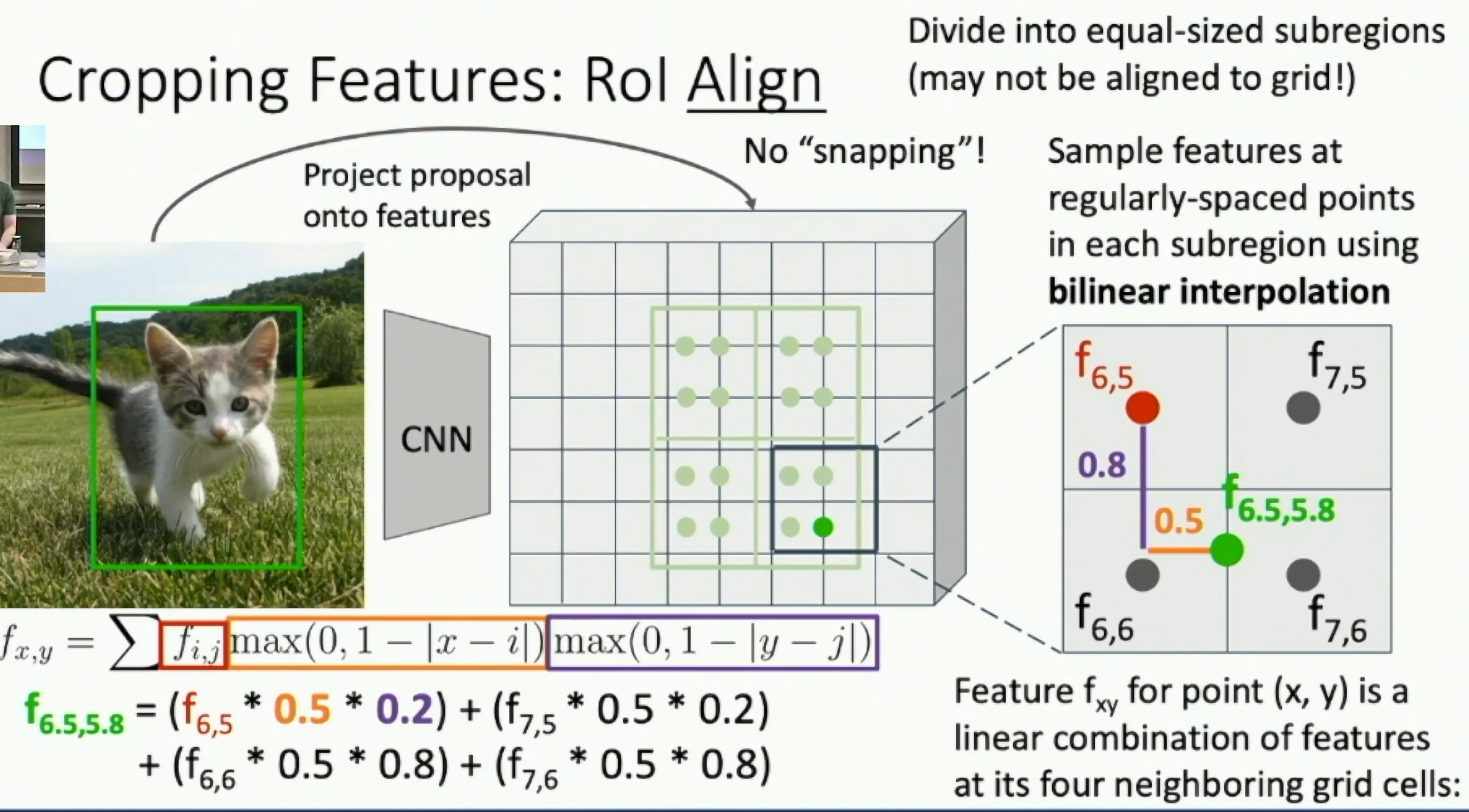
Fig: RoI Align
Fast R-CNN vs "Slow" R-CNN (ICCV 2015)
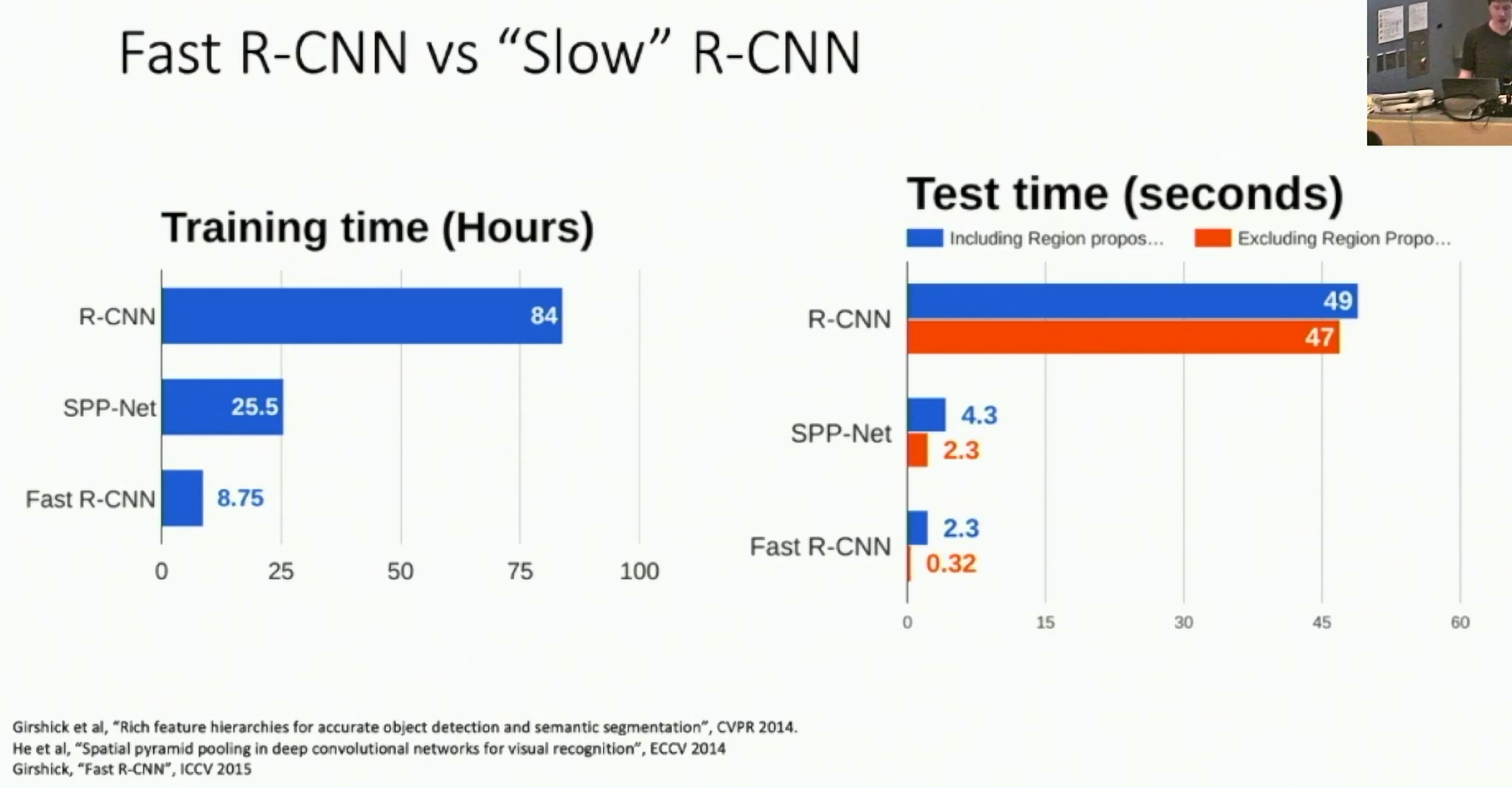
Fig: Fast R-CNN
Faster R-CNN: Learnable Region Proposals
Train a CNN to predict region proposals. NeurIPS 2015
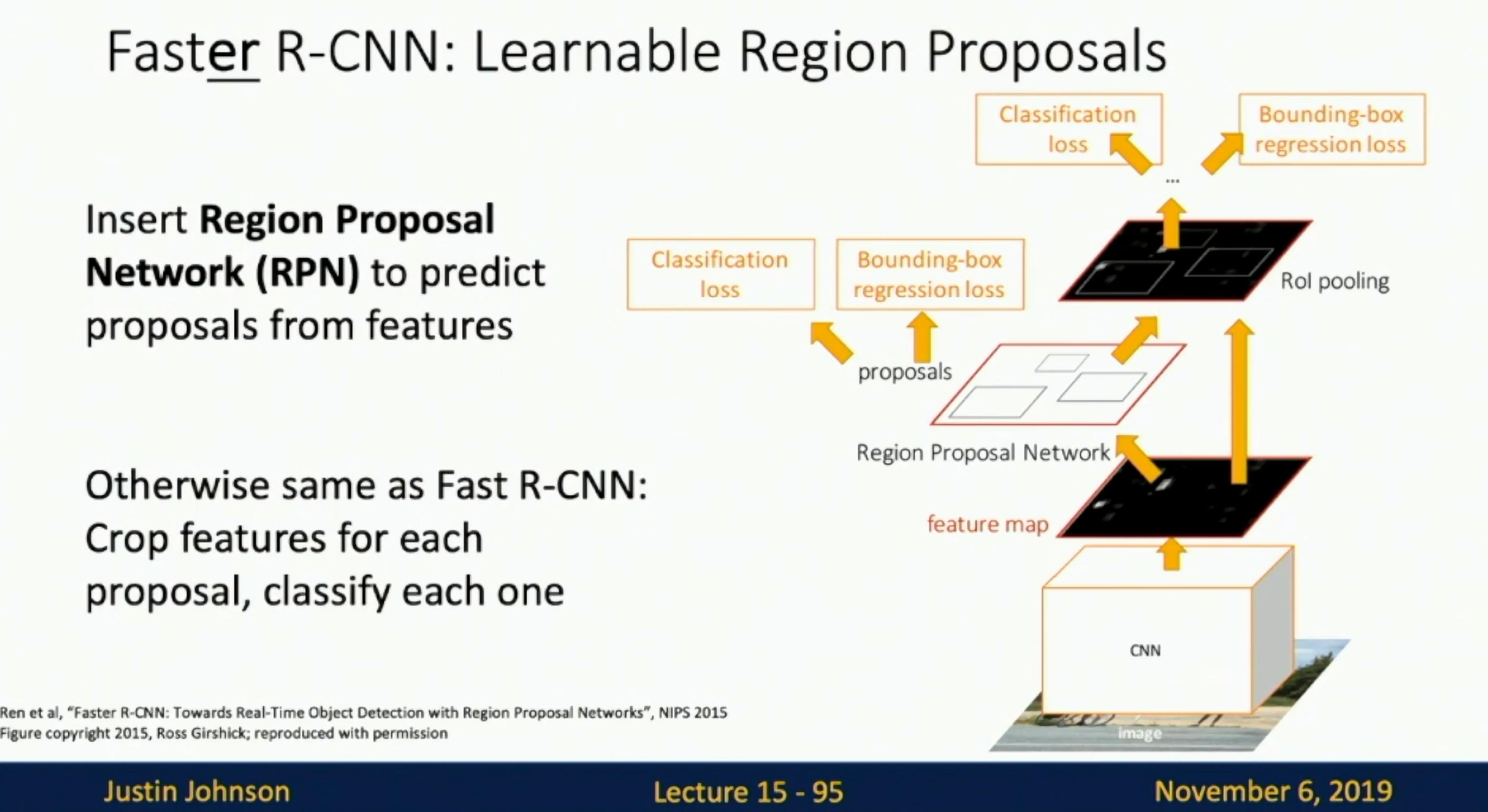
Fig: Faster R-CNN
Region Proposal Network (RPN):
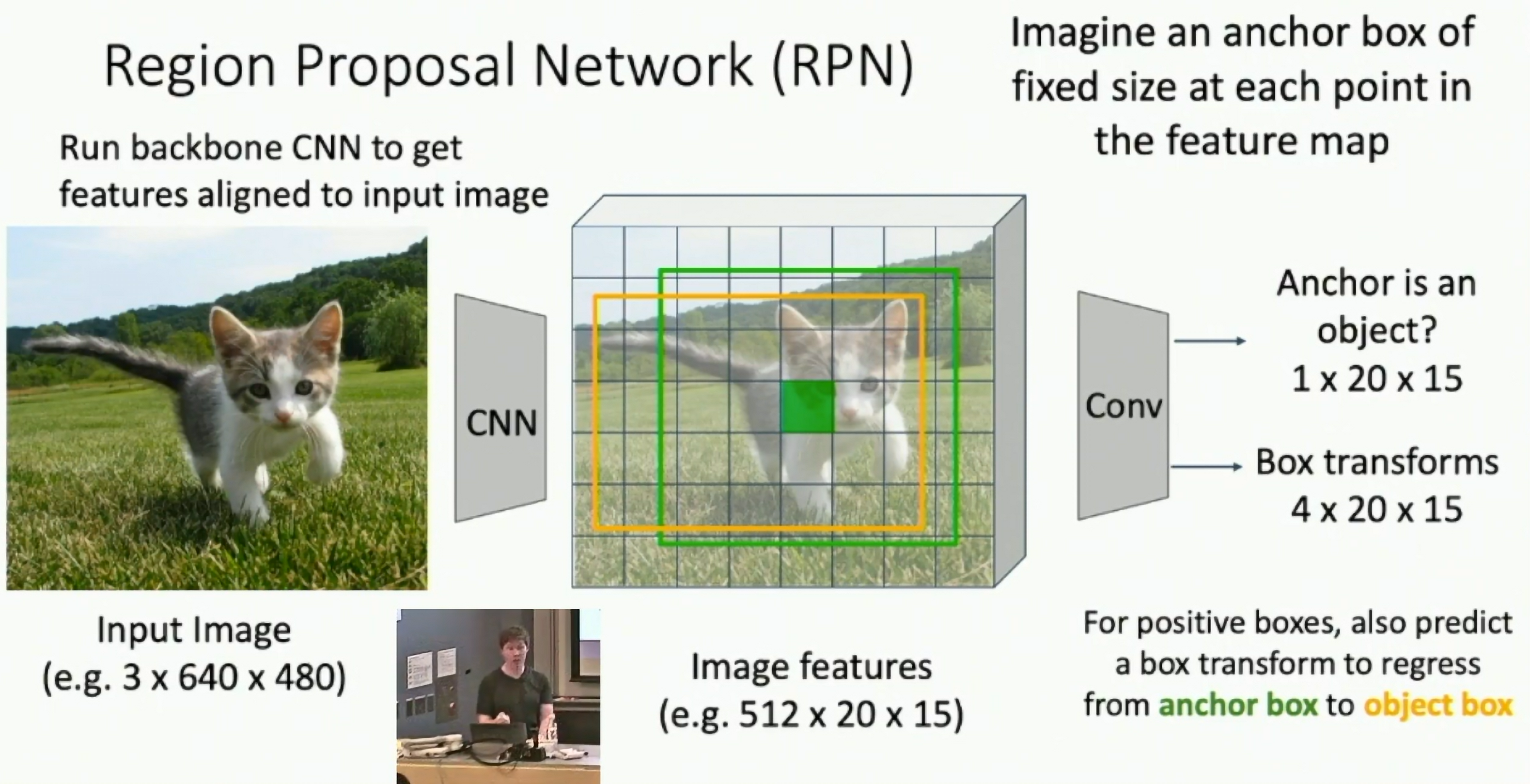
Fig: Region Proposal Network
Anchor box of fixed size at each point in the feature map.
At each point, predict whether the corresponding anchor contains an object or not (per-cell logistic regression, predict scores with conv layer.)
For positive boxes, also predict a box transform to regress from anchor to object box.
Problem: Anchor box may be too small or too large for the object. Solution: K Multi-scale anchors for each point.

Fig: Multi-scale anchors
Jointly with 4 losses:
- RPN classification loss: anchor box is object or not
- RPN regression loss: predict transform from anchor box to proposal box
- Object classification: classify proposals as background or object class
- Object regression: predict transform from a proposal box to object box
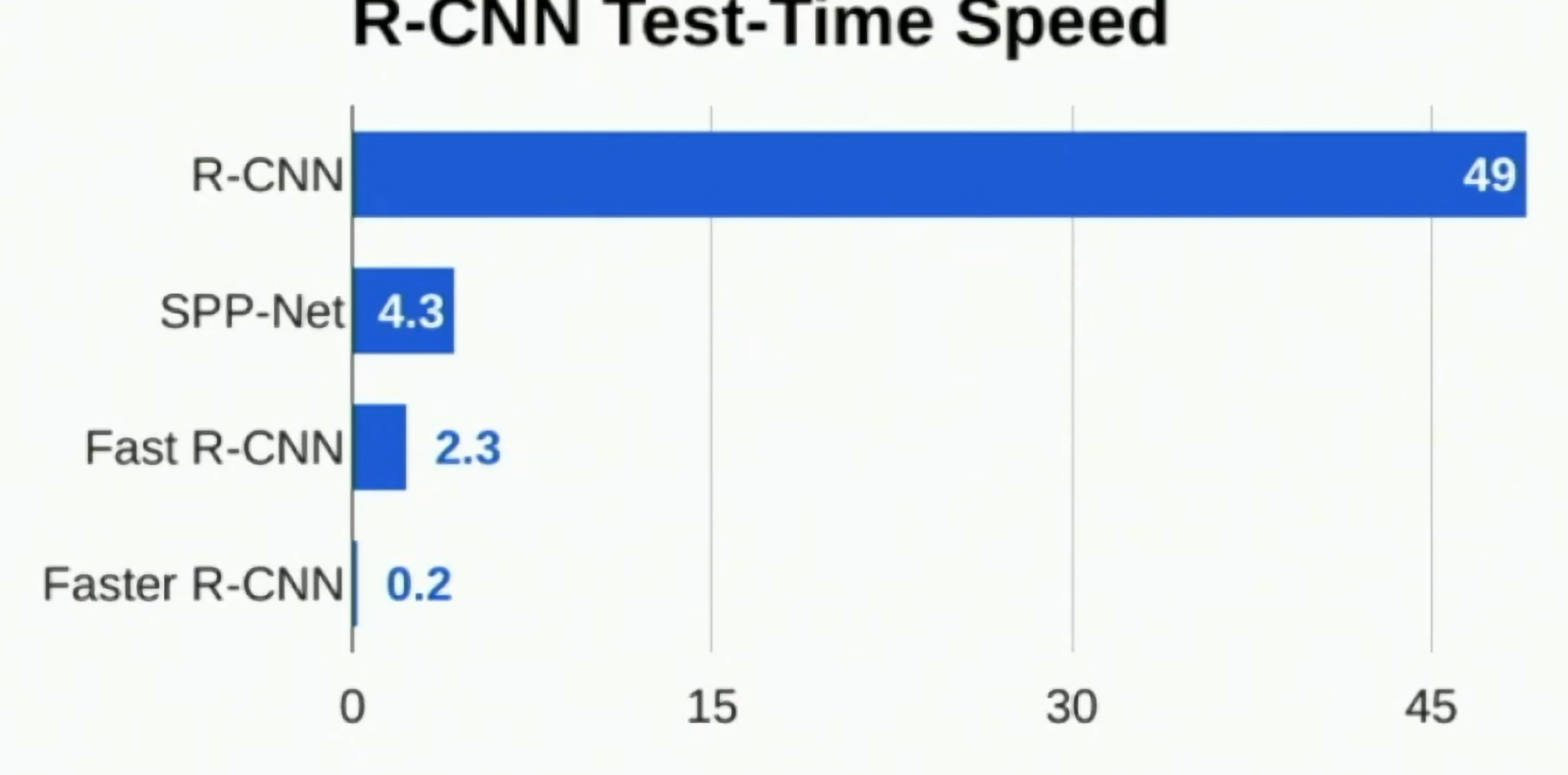
Fig: Faster R-CNN
Two stages:
First stage: Run once per image
- Backbone Network
- Region proposal network
Second stage: Run once per region
- Crop features: RoI pool/align
- Predict object class
- Prediction bbox offset
Single-Stage Object Detection
- YOLO: You Only Look Once. ECCV 2016
- Focal Loss for Dense Object Detection. ICCV 2017

Fig: YOLO
Detection without Anchors: CornerNet (ECCV 2018)
Use a backbone CNN to predict the heatmap of object upper-left corners and lower-right corners.
To match the upper-left and lower-right corners, use a "associative embedding" to predict the offset between the two corners.
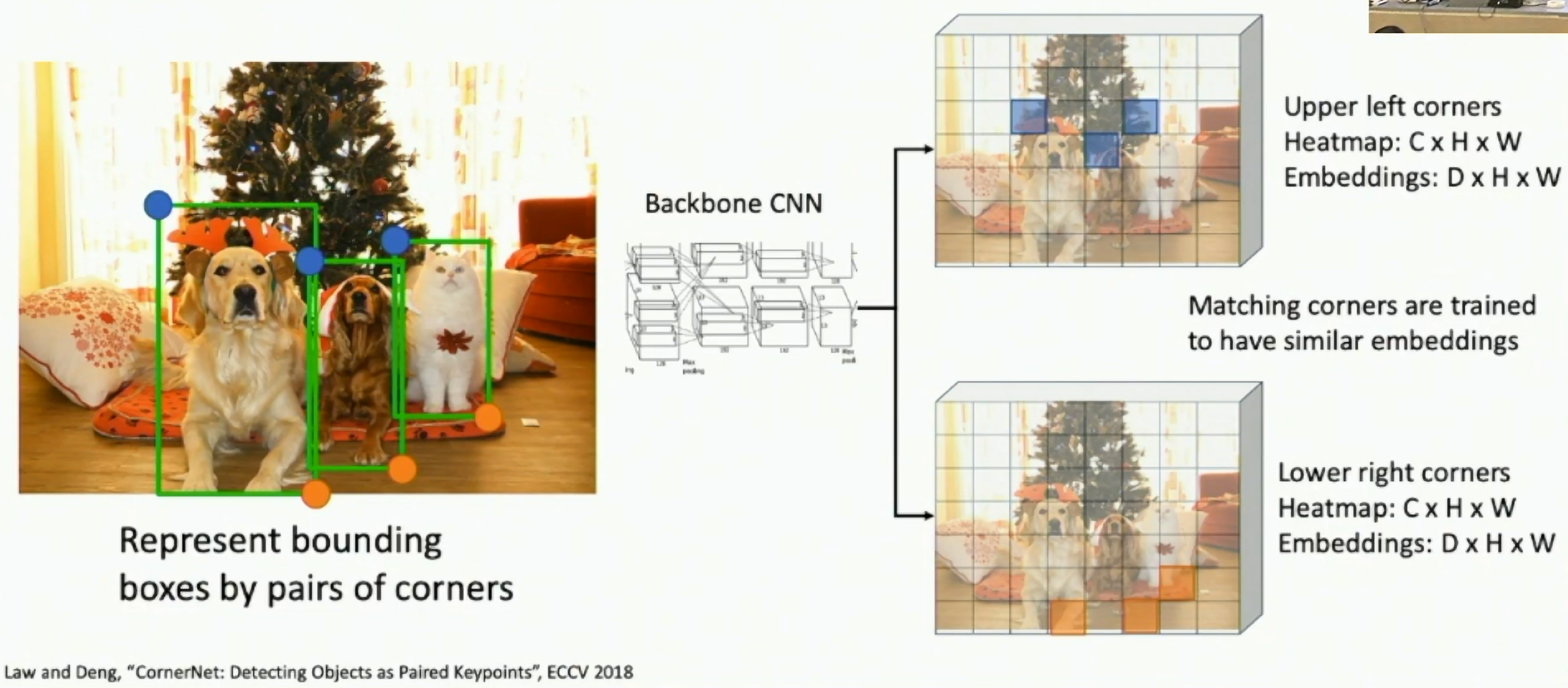
Fig: CornerNet
Comparison
Speed/accuracy trade-offs for modern convolutional object detectors CVPR 2017
Takeaways:
- Two stage method (e.g. Faster R-CNN) is more accurate but slower
- Single stage methods (e.g. YOLO, SSD) are faster but less accurate
- Bigger backbones improve performance, but are slower
- Nowadays, single stage methods are as good as two-stage methods
- Very big models work better
- Test-time augmentation pushes numbers up
- Big ensembles, more data, etc

Fig: Comparison
Object Detection: Open-Source Code
Don't implement it yourself (Unless you are working on the assignment)
Fast/Faster/Mask R-CNN, RetinaNet
Notice on Usage and Attribution
This note is based on the University of Michigan's publicly available course EECS 498.008 / 598.008 and is intended solely for personal learning and academic discussion, with no commercial use.
- Nature of the Notes: These notes include extensive references and citations from course materials to ensure clarity and completeness. However, they are presented as personal interpretations and summaries, not as substitutes for the original course content.
- Original Course Resources: Please refer to the official University of Michigan website for complete and accurate course materials.
- Third-Party Open Access Content: This note may reference Open Access (OA) papers or resources cited within the course materials. These materials are used under their original Open Access licenses (e.g., CC BY, CC BY-SA).
- Proper Attribution: Every referenced OA resource is appropriately cited, including the author, publication title, source link, and license type.
- Copyright Notice: All rights to third-party content remain with their respective authors or publishers.
- Content Removal: If you believe any content infringes on your copyright, please contact me, and I will promptly remove the content in question.
Thanks to the University of Michigan and the contributors to the course for their openness and dedication to accessible education.