UM-CV 16 Object Semantic Segmentation
Summary
Many Computer Vision Tasks: Classification, Semantic Segmentation, Object Detection, Instance Segmentation, Key Point Estimation, Dense Captioning, etc.
@Credits: EECS 498.007 | Video Lecture: UM-CV 5 Neural Networks
Personal work for the assignments of the course: github repo.
Notice on Usage and Attribution
These are personal class notes based on the University of Michigan EECS 498.008 / 598.008 course. They are intended solely for personal learning and academic discussion, with no commercial use.
For detailed information, please refer to the complete notice at the end of this document
Object Segmentation
Label each pixel in an image with a category label. Do not differentiate instances, onlu care about pixels.
Intuition: Sliding window classiffier, but for each pixel.
Fully Convolutional Networks (FCNs)
The size of the output is the same as the input. Make predictions for pixels all at once!

Fig: FCNs
Long et al. 2015 proposed FCNs for semantic Segmentation
Problems
- Effective receptive field size is linear in number of conv layers: With L 3x3 conv layers, the receptive field is 1+2L
- Convolution on high res images is expensive
With down sampling and upsampling inside the network.
Noh et al, Learning Deconvolution Network for Semantic Segmentation"
Unpooling
Bed of Nails,KNN, Bilinear Interpolation
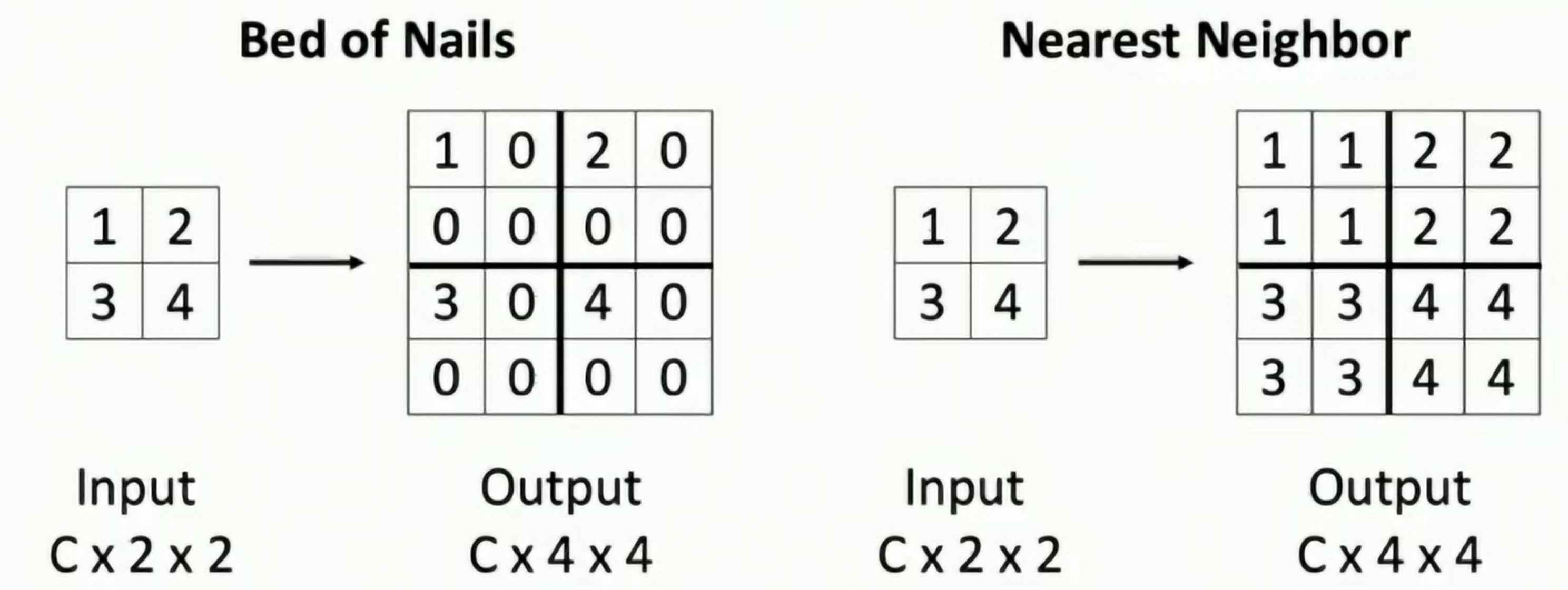
Fig: Unpooling
Cubic Interpolation, Bicubic Interpolation (两次立方)
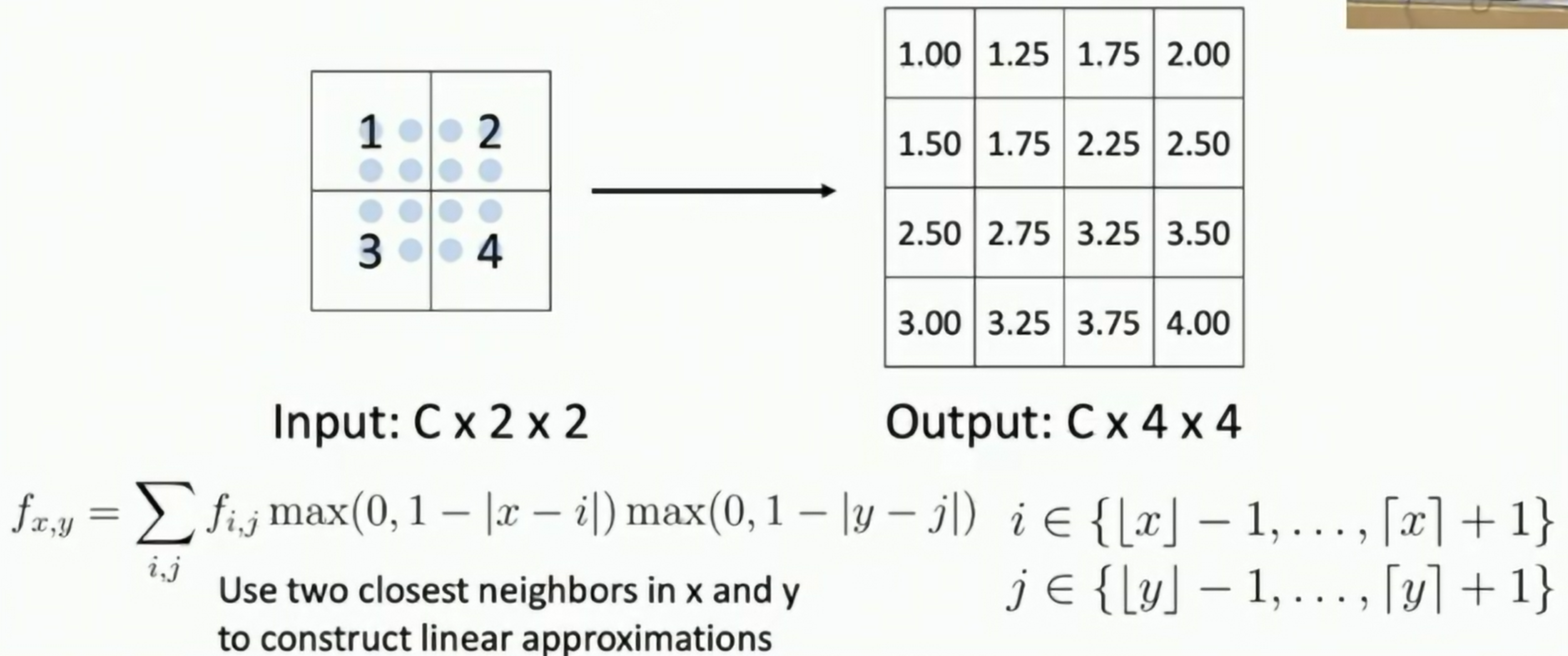
Fig: Cubic Interpolation
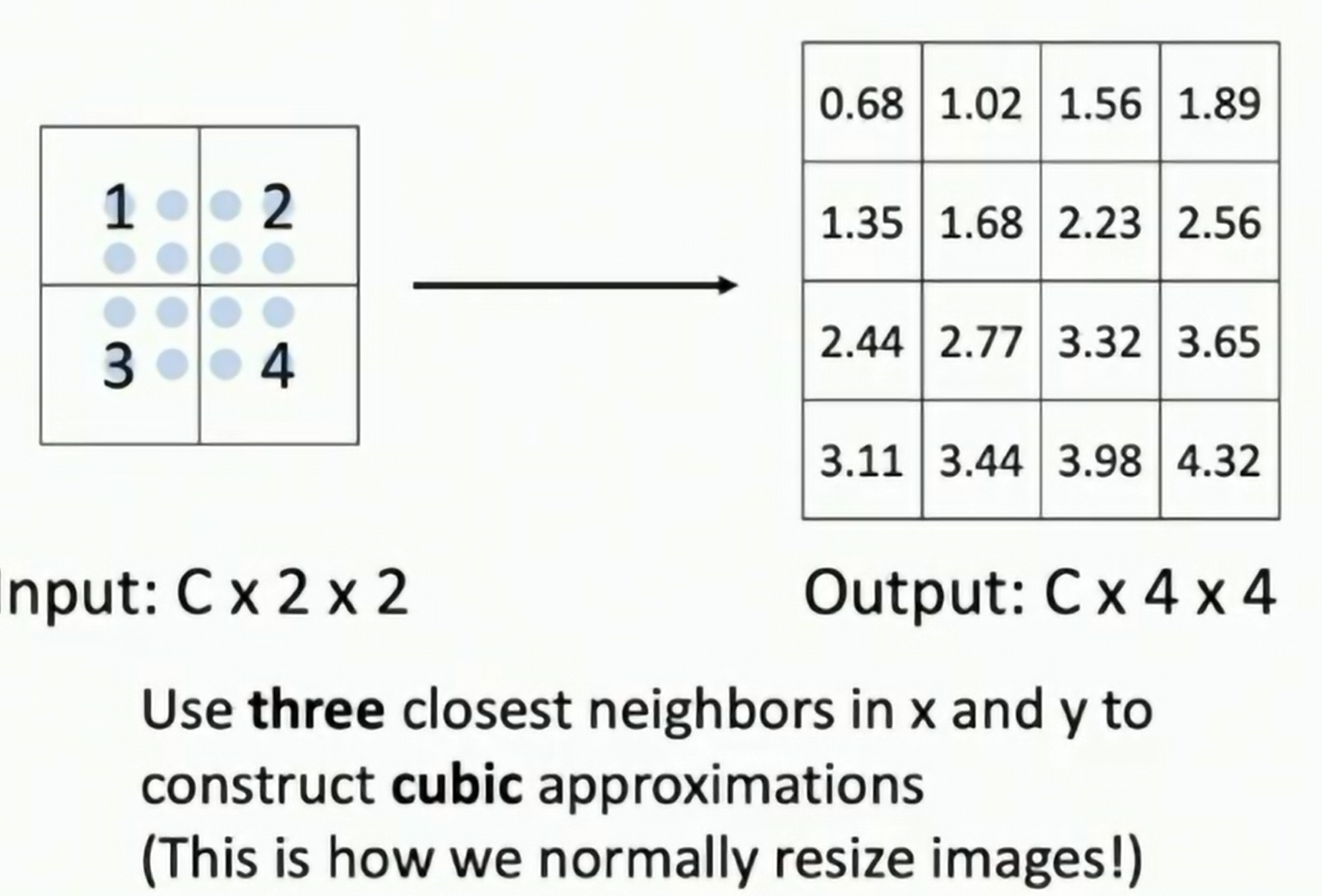
Fig: Bicubic Interpolation
Max Unpooling: Remember the location of the max value in the pooling layer and put it back in the unpooling layer.
Noh et al, Learning Deconvolution Network for Semantic Segmentation
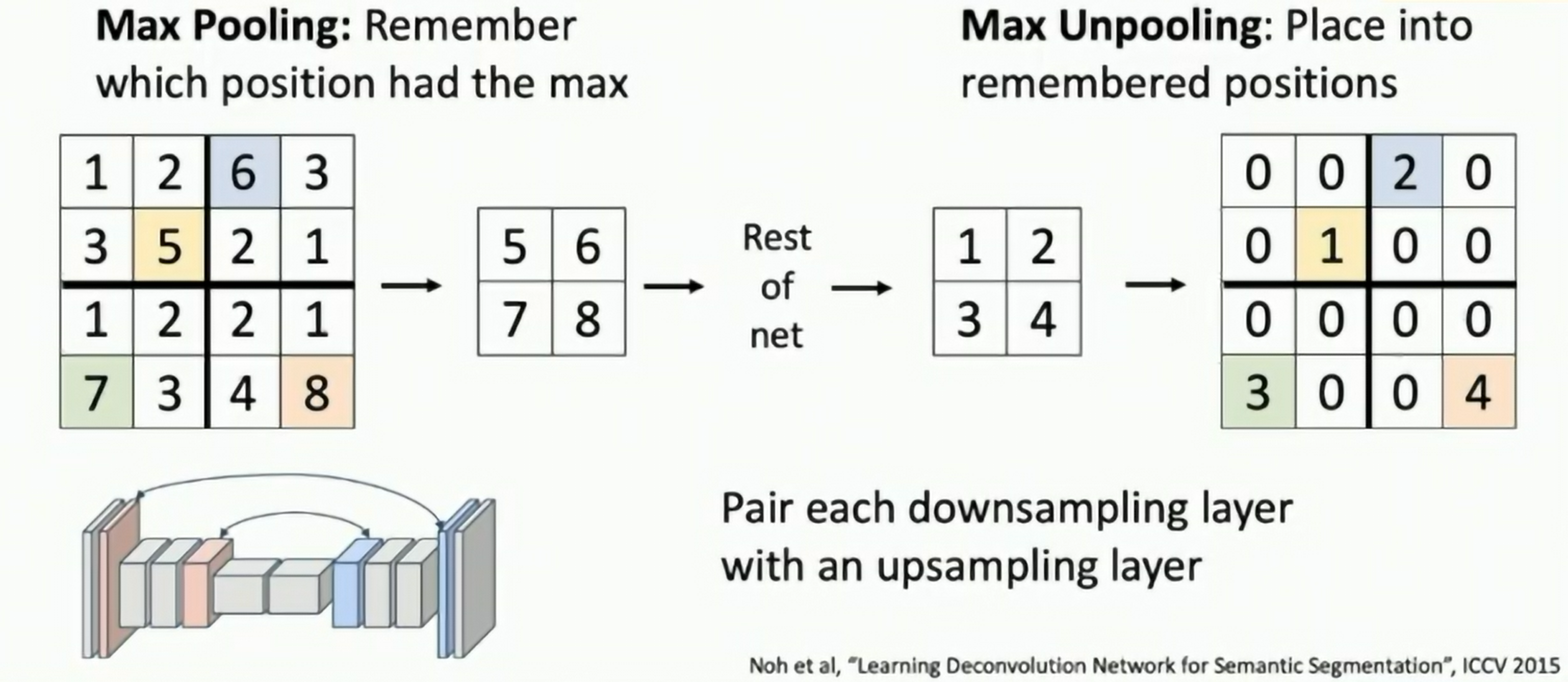
Fig: Max Unpooling
Pair each downsampling layer with an upsampling layer.
Transposed Convolution (Deconvolution)
Idea: Convolution with stride > 1 is "learnable downsampling", can we use stride < 1 for "learnable upsampling"?
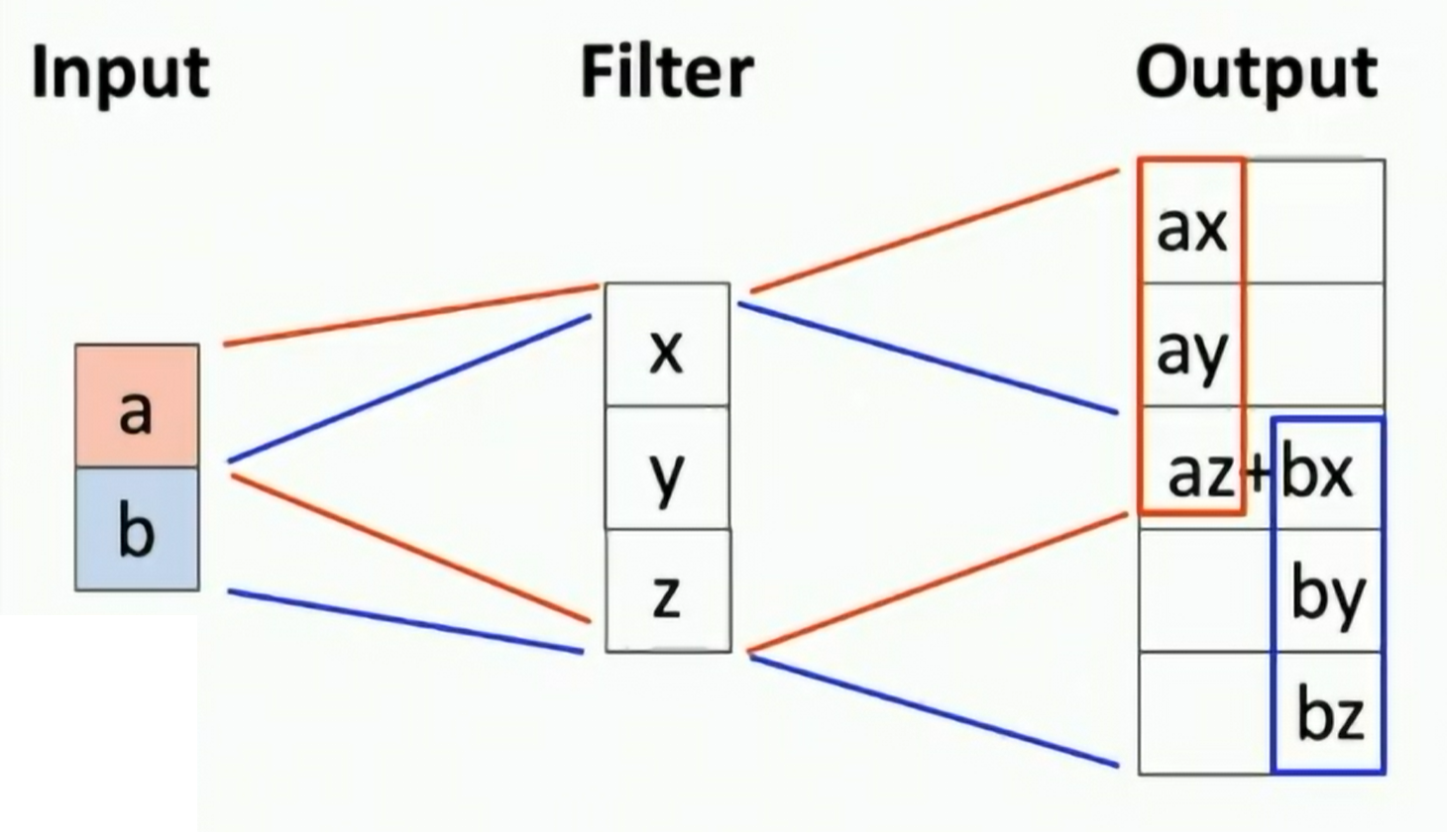
Fig: Transposed Convolution
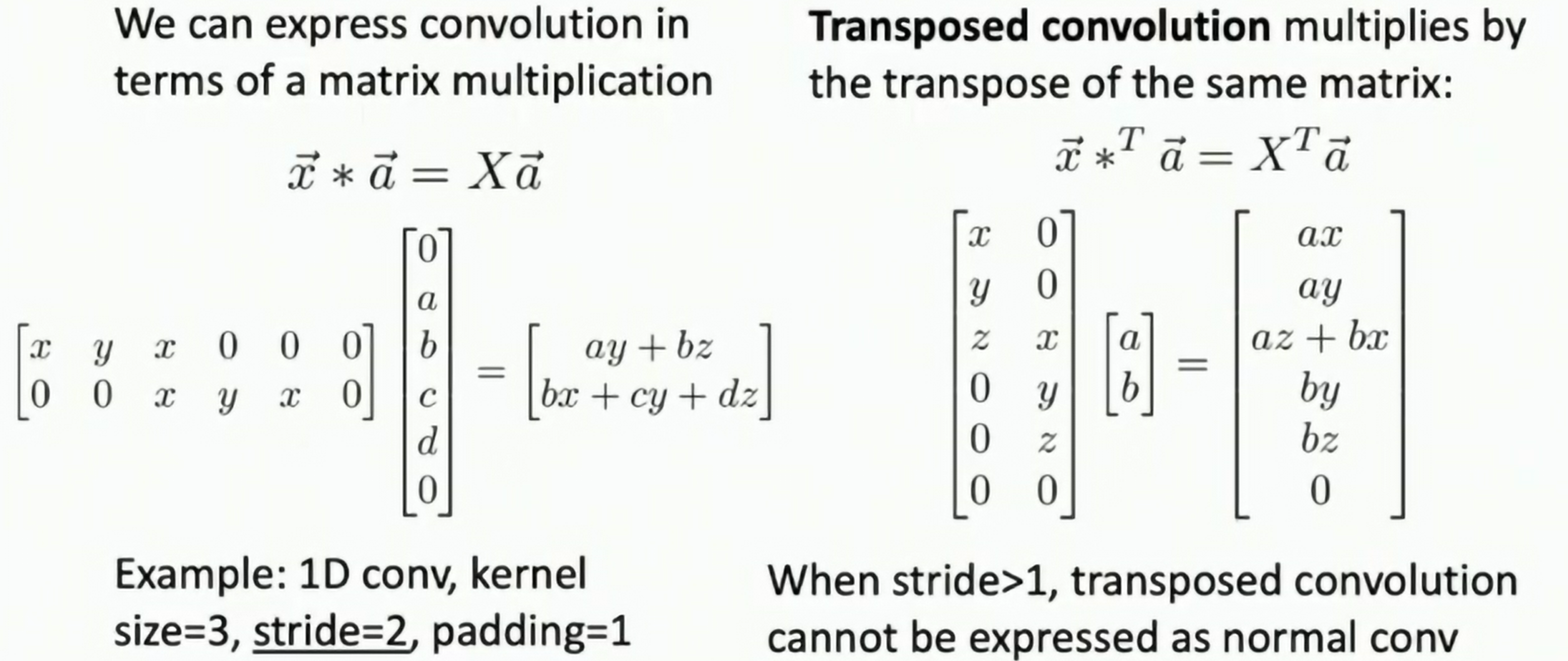
Fig: Transposed Convolution
Instance Segmentation
Semantic segmentation merges objects of the same class.
Things and stuff: Things are object categories that can be separated into object instances, while stuff is object categories that cannot be separated into object instances.(e.g. sky, grass)
Object Detection: Detects individual object instances, but only gives box (Only things!)
Semantic Segmentation: Gives per-pixel labels that does not differentiate between instances.
Instance Segmentation: Detect all objects in the image and identify the pixels that belong to each object.
Approach: Perform object detection, then predict a segmentation mask for each object.
Mask R-CNN
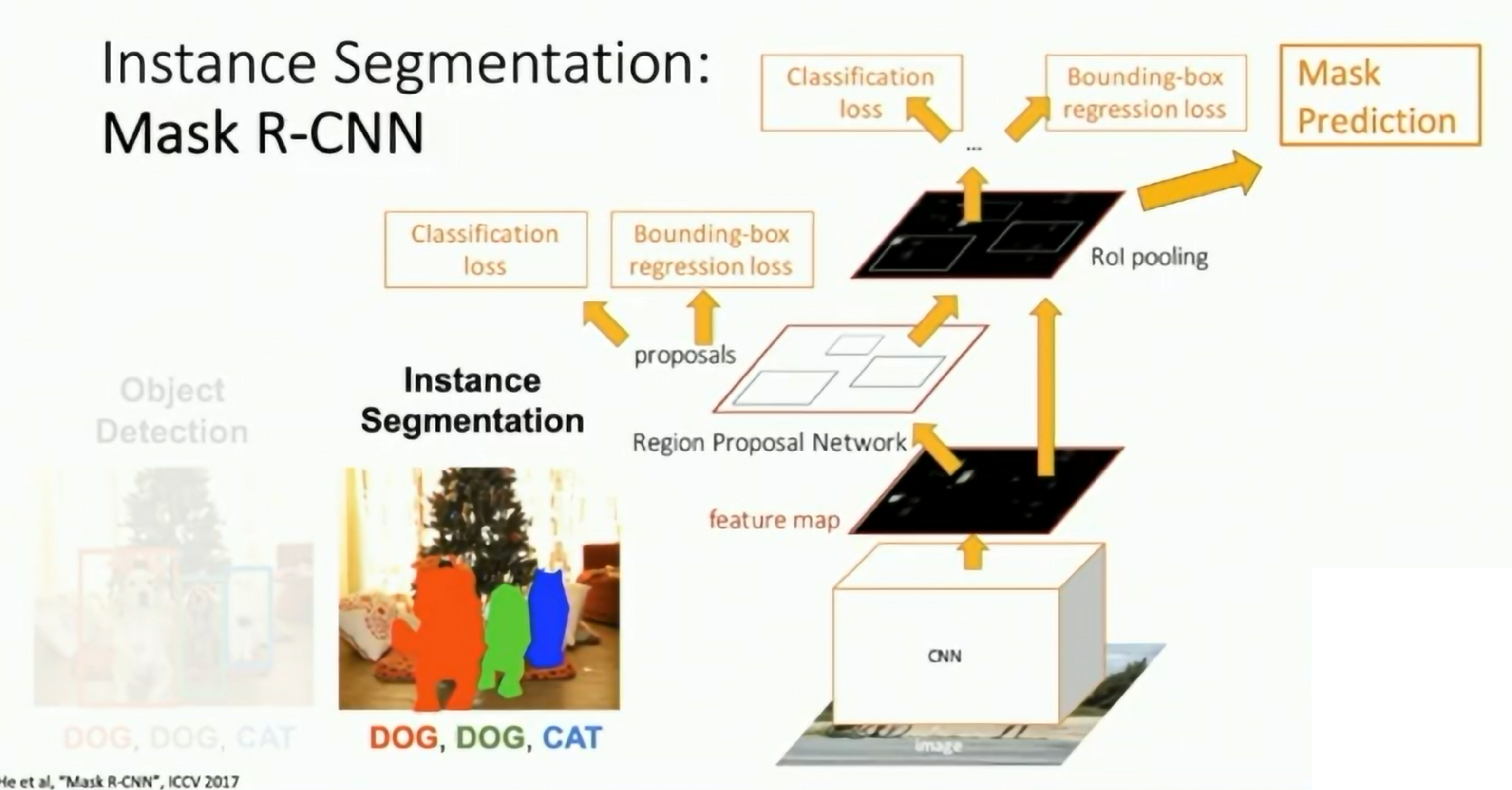
Fig: Mask R-CNN
- Region Proposal Network (RPN): Predicts bounding boxes
- Semantic Segmentation for each bounding boxes

Fig: Example Targets
Panoptic Segmentation
Panoptic 中文的意思是全景,全视角的意思。
Label all pixels in the image, and for thing categories, differentiate between instances.

Fig: Panoptic Segmentation
CVPR 2019: Panoptic Feature Pyramid Networks
Beyond Instance Segmentation
Key Point Estimation
Predict the location of keypoints on an object.
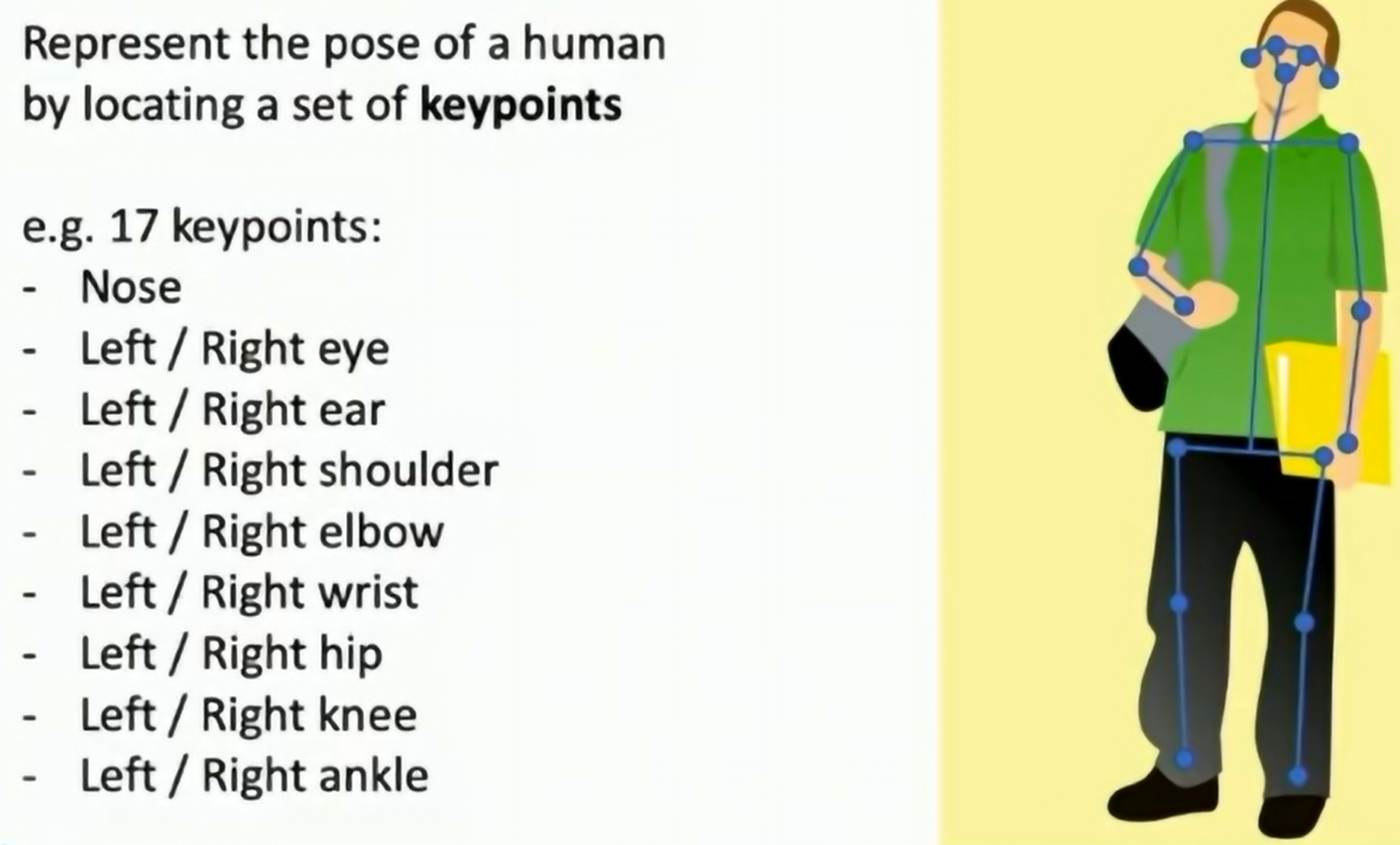
Fig: Key Point Estimation
Mask R-CNN: keypoints
- Add a keypoint head to predict the location of keypoints
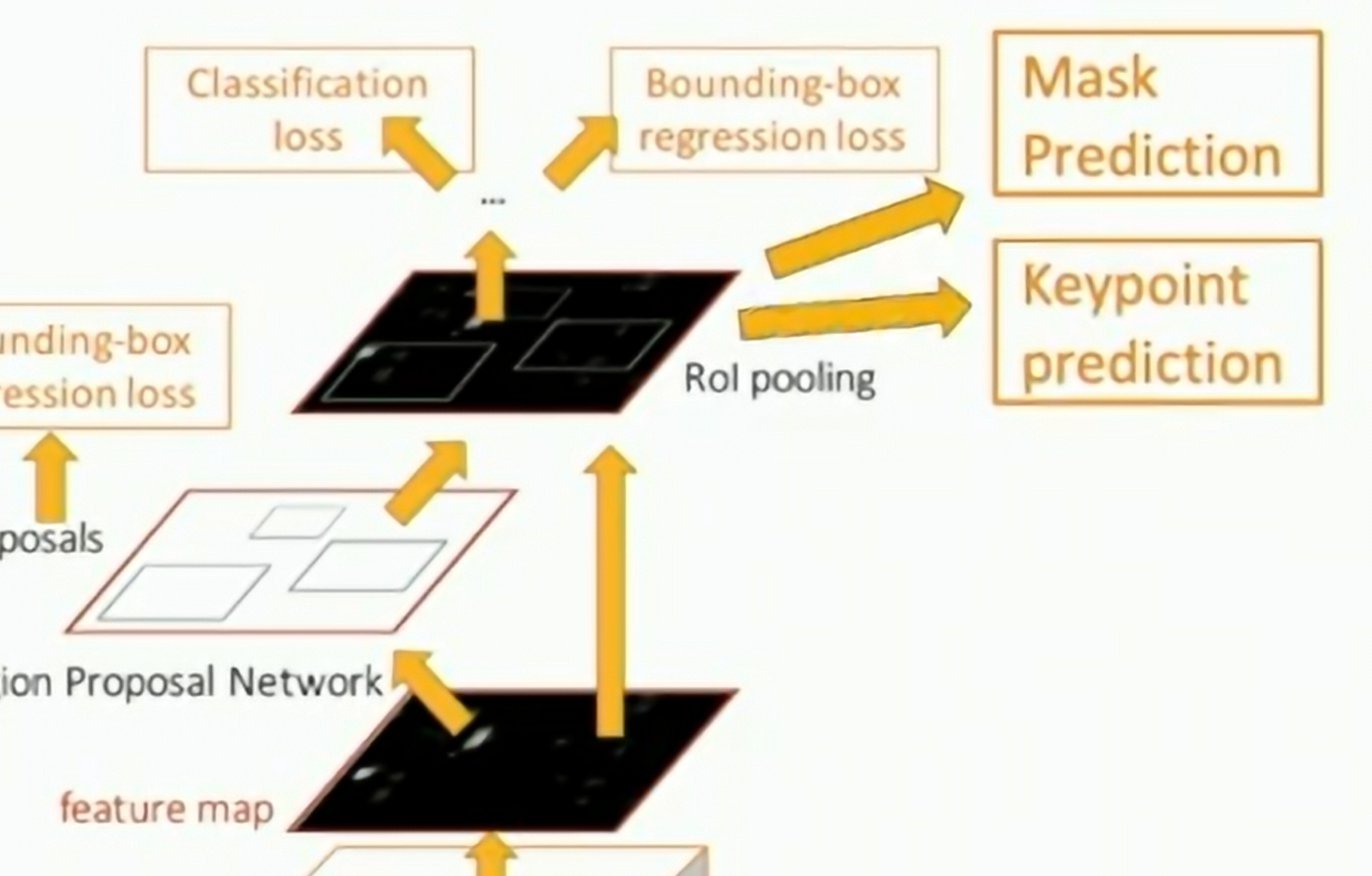
Fig: Mask R-CNN Keypoints
Joint Instance Segmentation and Keypoint (Pose) Estimation
General Idea: Add Per-region "Heads" to Fasrer/ Mask R-CNN!
Dense Captioning
3D Shape Prediction: Mask R-CNN + Mesh Head
Notice on Usage and Attribution
This note is based on the University of Michigan's publicly available course EECS 498.008 / 598.008 and is intended solely for personal learning and academic discussion, with no commercial use.
- Nature of the Notes: These notes include extensive references and citations from course materials to ensure clarity and completeness. However, they are presented as personal interpretations and summaries, not as substitutes for the original course content.
- Original Course Resources: Please refer to the official University of Michigan website for complete and accurate course materials.
- Third-Party Open Access Content: This note may reference Open Access (OA) papers or resources cited within the course materials. These materials are used under their original Open Access licenses (e.g., CC BY, CC BY-SA).
- Proper Attribution: Every referenced OA resource is appropriately cited, including the author, publication title, source link, and license type.
- Copyright Notice: All rights to third-party content remain with their respective authors or publishers.
- Content Removal: If you believe any content infringes on your copyright, please contact me, and I will promptly remove the content in question.
Thanks to the University of Michigan and the contributors to the course for their openness and dedication to accessible education.