UM-CV 18 Videos
Summary: Video Classification, CNN Architectures for Videos, Two-Stream Networks, Recurrent Structures, Spatial-Temporal Detection, and more.
@Credits: EECS 498.007 | Video Lecture: UM-CV
Personal work for the assignments of the course: github repo.
Notice on Usage and Attribution
These are personal class notes based on the University of Michigan EECS 498.008 / 598.008 course. They are intended solely for personal learning and academic discussion, with no commercial use.
For detailed information, please refer to the complete notice at the end of this document
Intro
A video is a sequence of images over time. We can think of a video as a 4D tensor: (T, C, H, W).
- T: time, C: channels, H: height, W: width
Today: Video Classification
Images: Recognize objects
- Dog, Cat, Fish, Truck
Videos: Recognize actions
- Swimming, Running, Jumping, Eating, Standing
Training on Clips
Uncompressed video: 3 bytes per pixel
- SD (640x480):~1.5 GB per minute
- HD (1920x1080): ~5 GB per minute
Solution: Train on short clips
- Low fps and low spatial resolution. e.g. T=16, H=W=112 (3.2 seconds at 5 fps, 588KB) -Testing: Run model on different clips, average predictions.
CNN Architectures for Videos
Single-Frame CNN
Simple idea: train a normal 2D CNN to classify video frames independently and average the predictions. On the contrary, this is a very strong baseline for video classification.

Fig: Single-Frame CNN
Late Fusion
- Single frame CNN + FC layers
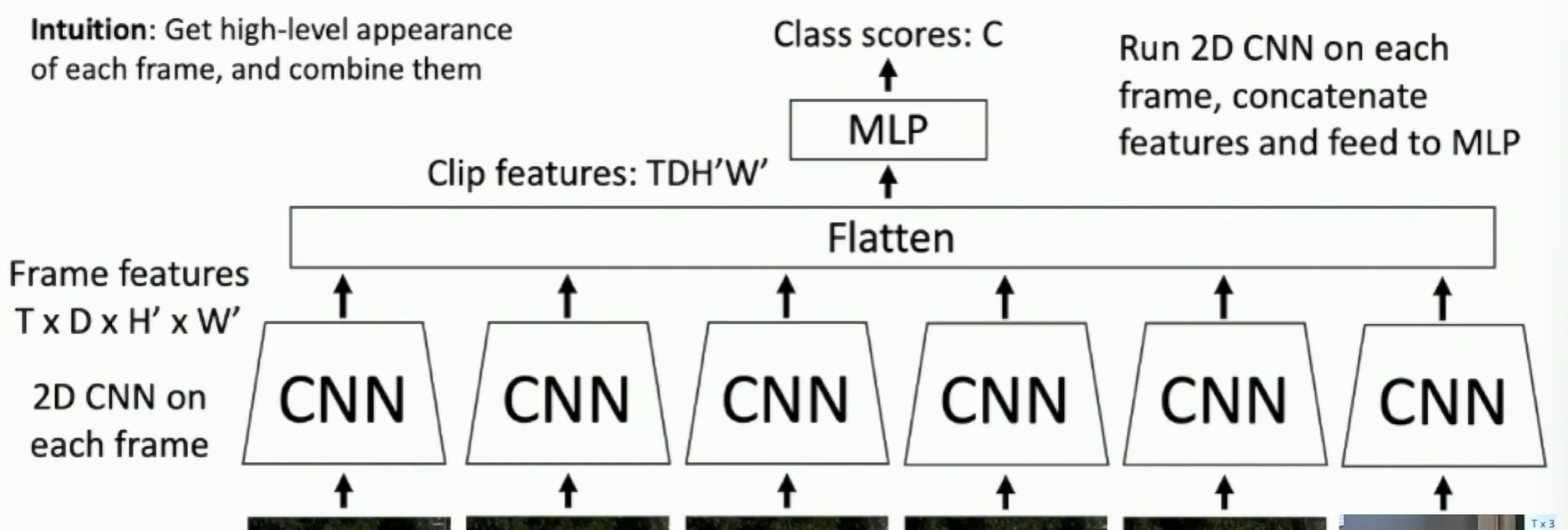
Fig: Late Fusion
- with pooling

Fig: Late Fusion with Pooling
Problem: Hard to compare low-level motion between frames.
Early Fusion
Large Scale Video Classification with Convolutional Neural Networks, CVPR 2014
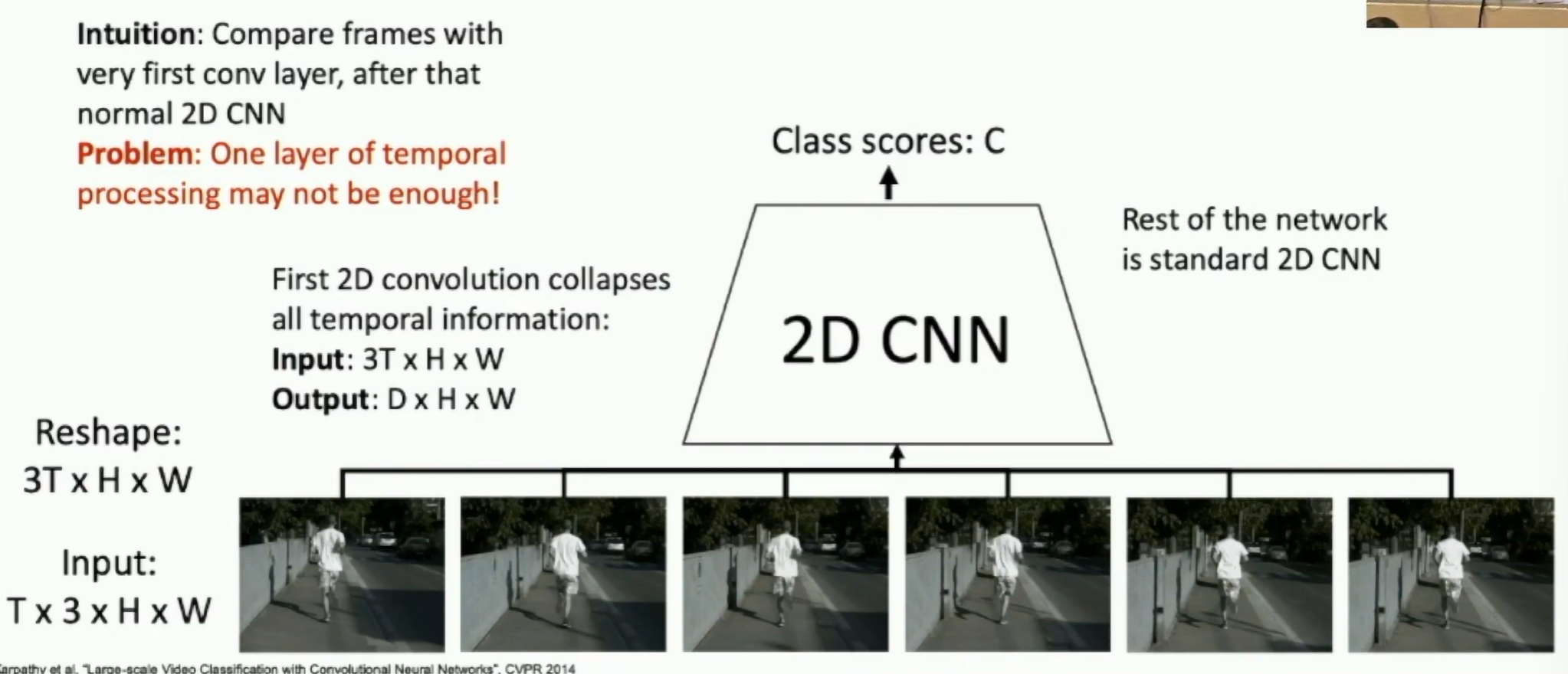
Fig: Early Fusion
3D CNN (Slow Fusion)
Ji et al., 3D Convolutional Neural Networks for Human Action Recognition, TPAMI 2010
Comparison
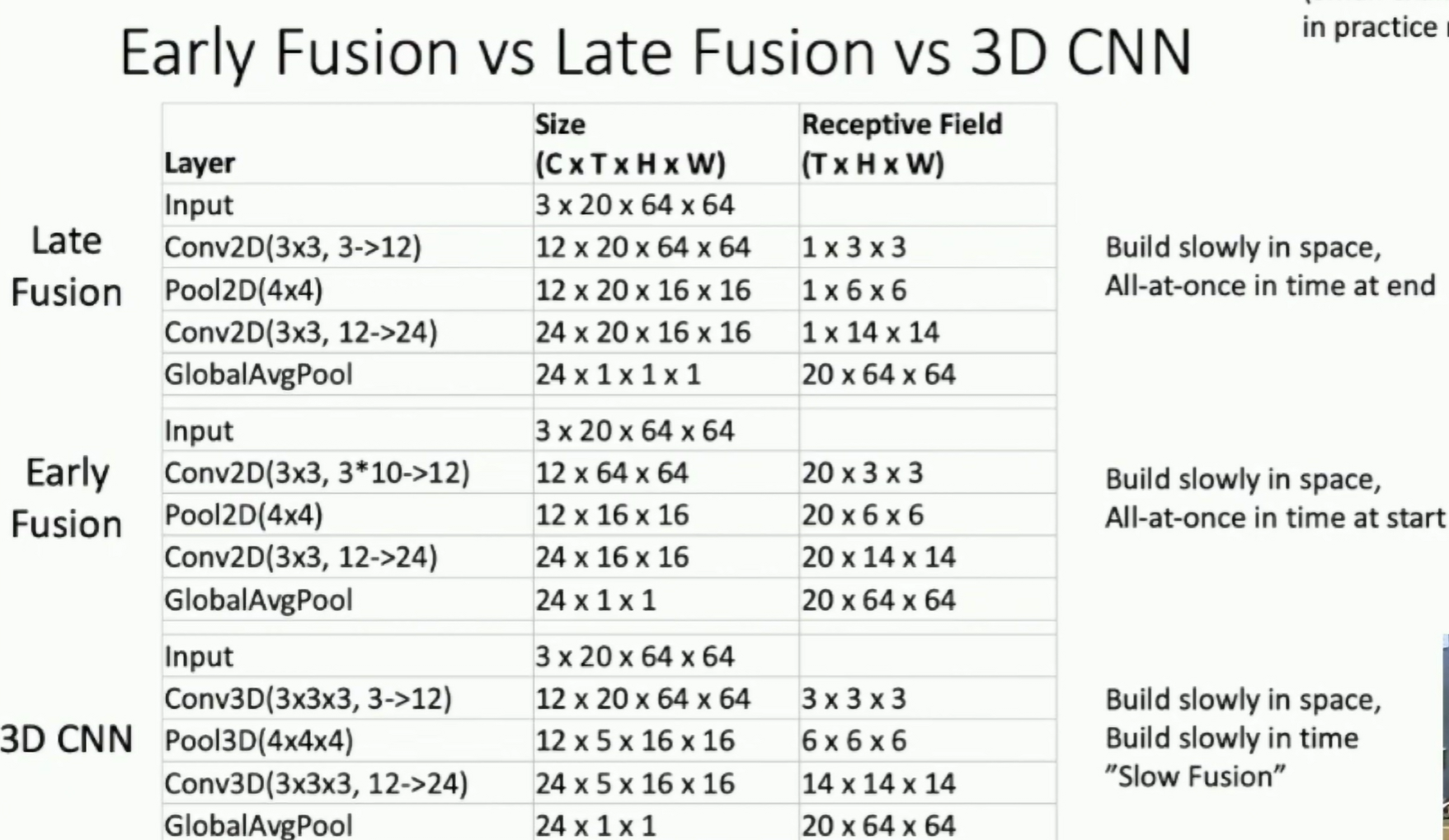
Fig: Early Fusion vs Late Fusion vs 3D CNN
(In practice, we use much larger models than the ones shown in the figure above)
2D Conv vs 3D Conv
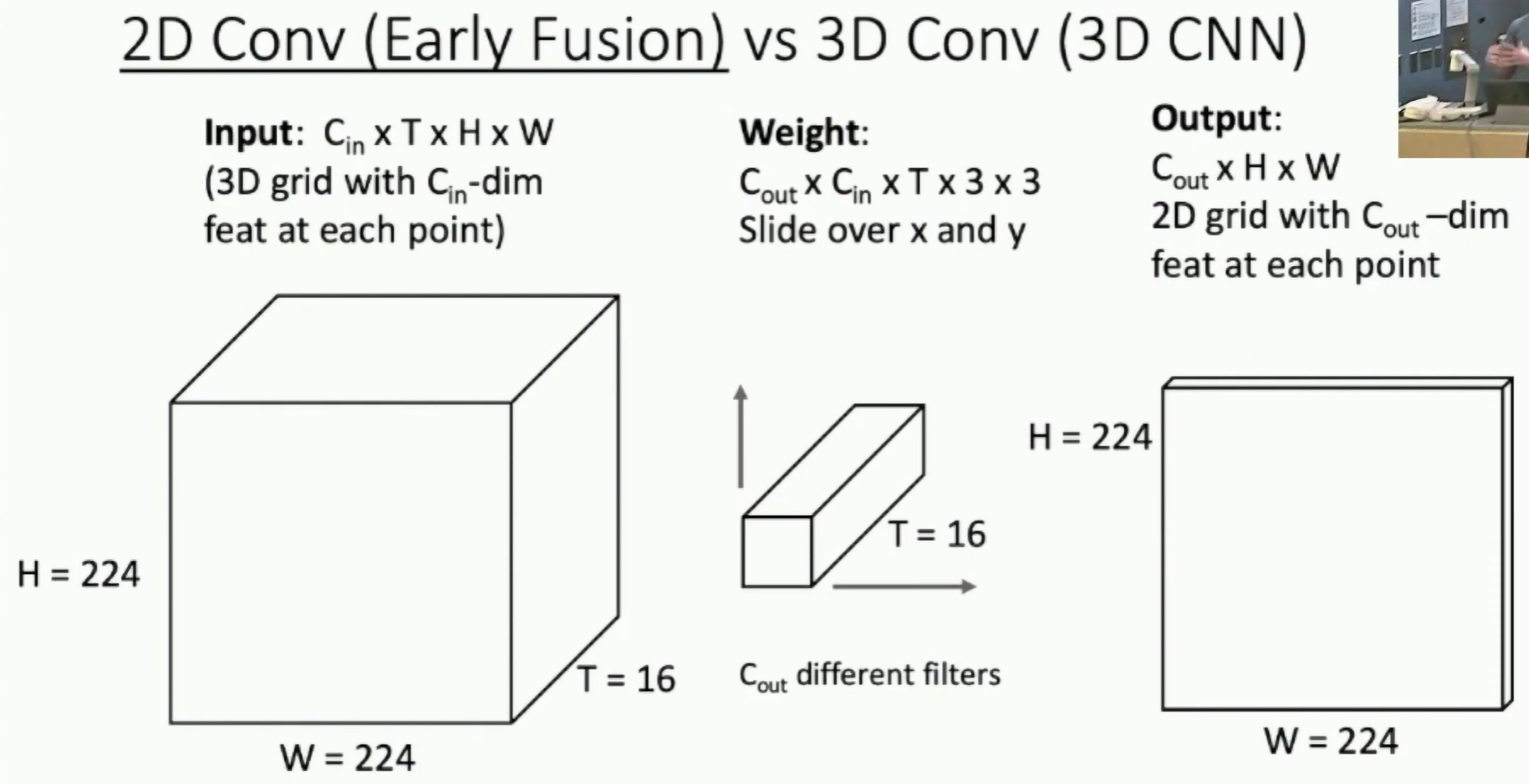
Fig: 2D Conv vs 3D Conv
Problem: No temporal shift-invariance!
3D Conv filters are shift invariant since each filter slides over time.
Visualization of the first layer filters of a 3D temporal convnet: Large-scale Video Classification with Convolutional Neural Networks, CVPR 2014
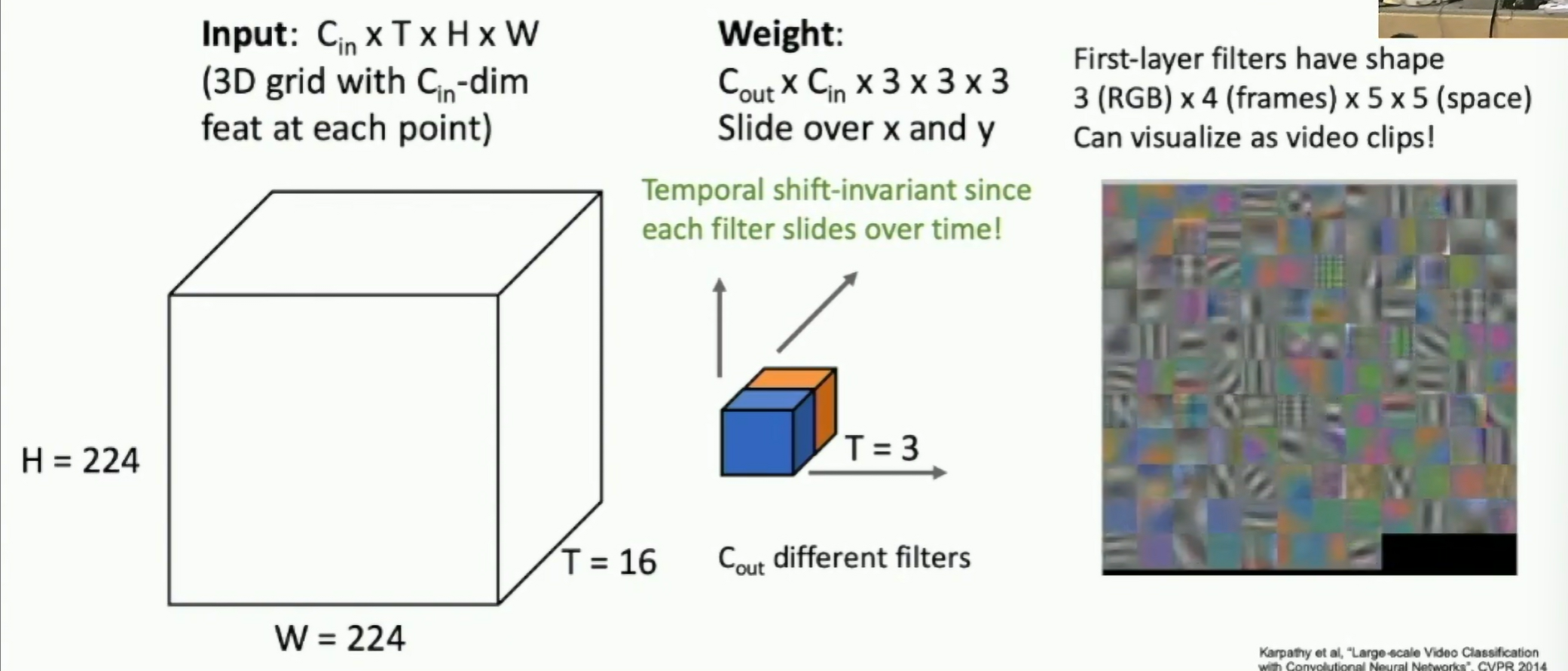
Fig: 3D Conv Filters
Example Video Dataset: Sports-1M
1M YouTube videos of sports events. 487 classes.
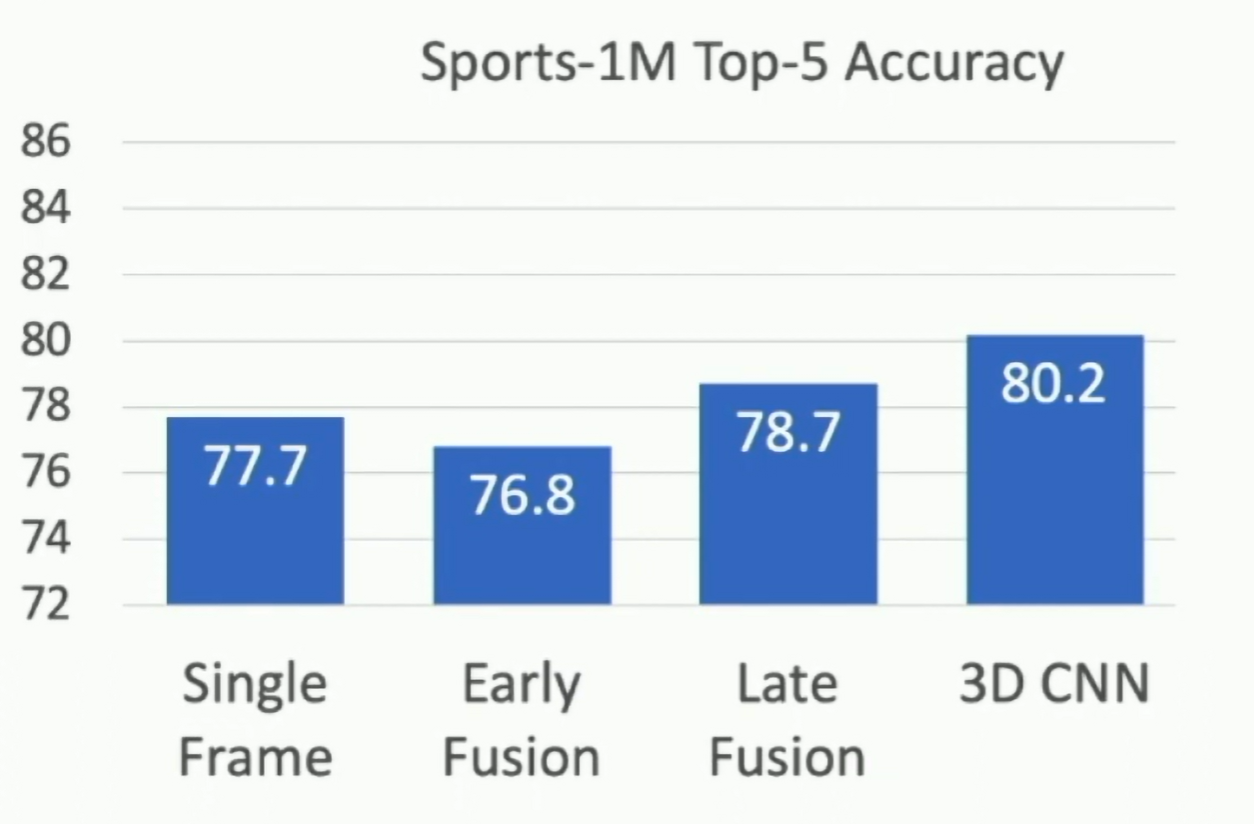
Fig: Sports-1M Top-5 Accuracy (in 2014)
Now 3D CNN architectures are much better.
C3D Architecture
Tran et al., Learning Spatiotemporal Features with 3D Convolutional Networks, ICCV 2015
"The VGG of 3D ConvNets"
Problem: 3x3x3 conv is very computationally expensive.
- AlexNet: 0.7 GFLOP
- VGG-16: 13.6 GFLOP
- C3D: 39.5 GFLOP (2.9x VGG!)
Insights: We need to treat time and space differently.
Two-Stream Networks
Human's brain is treating motion differently from static images. We do not need to see the pixels to recognize actions.
Optical Flow
Image at frame t and t+1: Optical flow is a 2D vector field that represents the motion of pixels between the two frames.
Two-Stream Networks: Simonyan and Zisserman, Two-Stream Convolutional Networks for Action Recognition in Videos, NIPS 2014
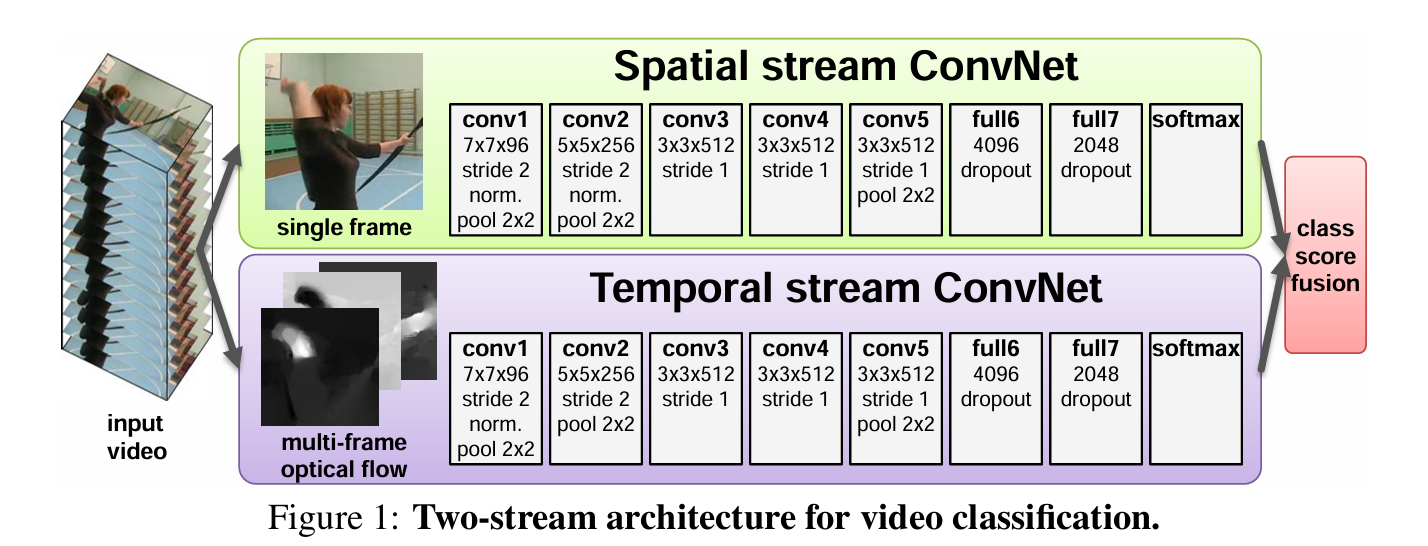
Fig: Two-Stream Networks
At test time we take an average of the predictions of the two streams.
Results(2014)
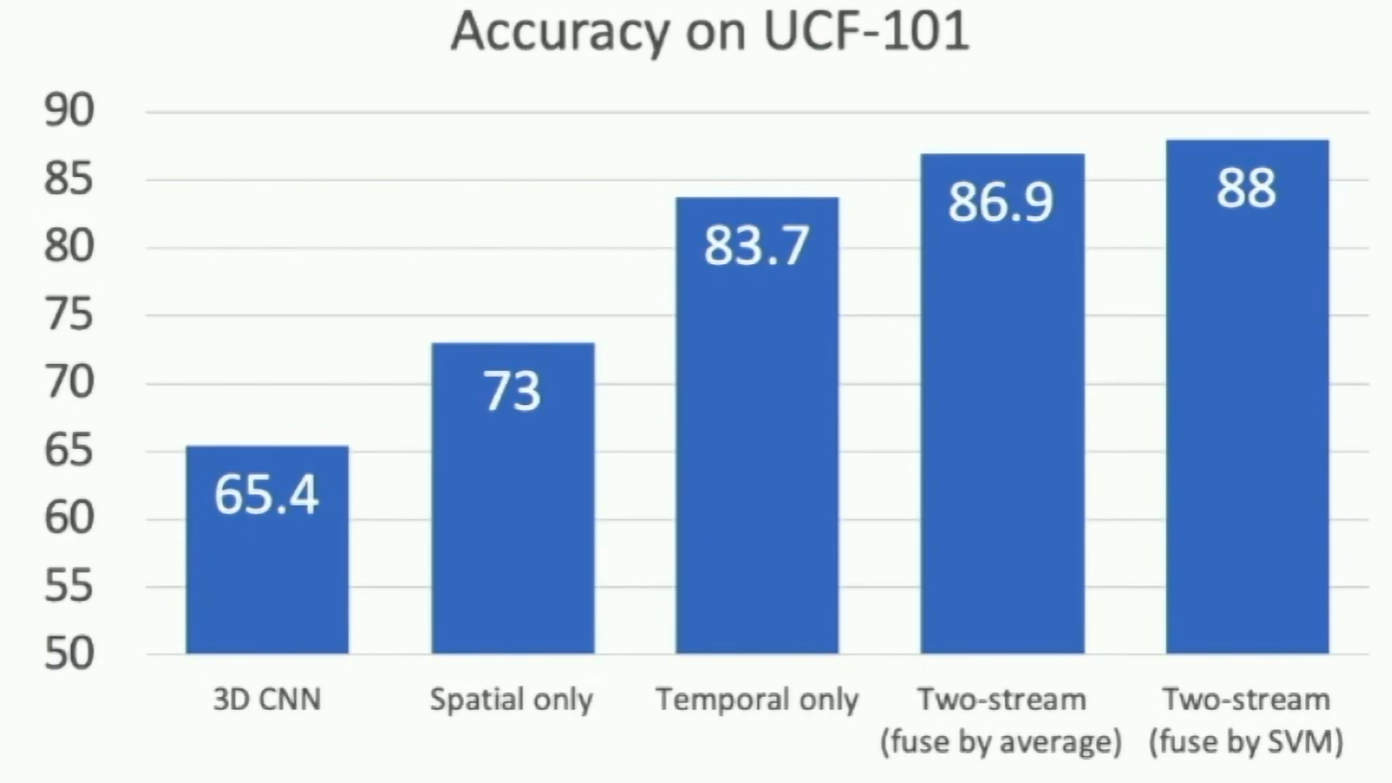
Fig: Two-Stream Networks Results
Recurrent Structures
Use recurrent neural networks (RNNs) to model long-term temporal structure.
in 2011: way ahead of its time!
Baccouche et al, Sequential Deep Learning for Human Action Recognition, 2011
We can use a similar structure to Multi-layer RNN to process videos.
Ballas et al, Delving Deeper into Convolutional Networks for Learning Video, ICLR 2016
Recurrent CNN: Infinite temporal extent (convolutional)
Problem: RNNs are slow for long sequences.
Spatio-Temporal Self Attention (Nonlocal Block)
Wang et al, Non-local Neural Networks, CVPR 2018
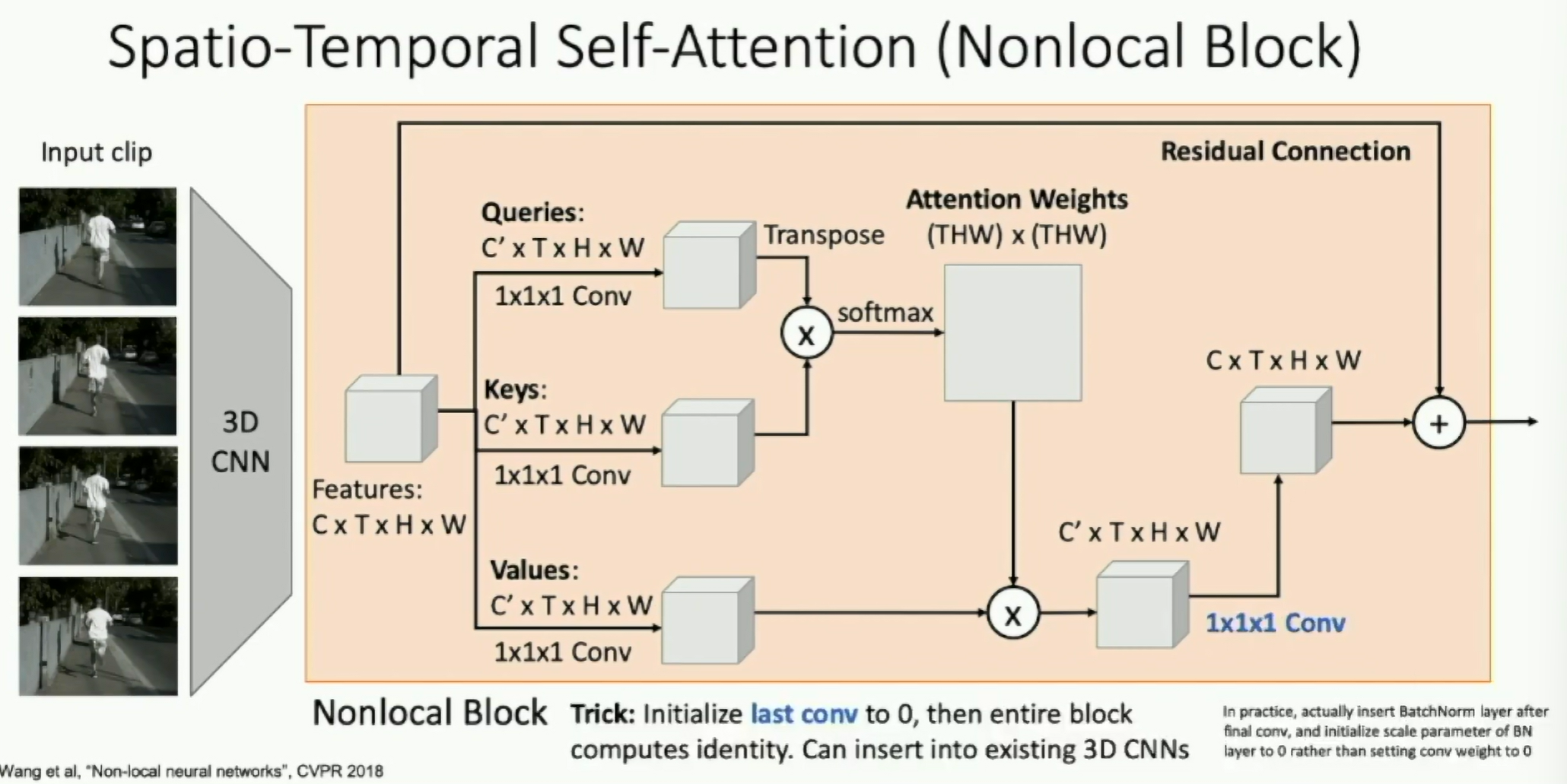
Fig: Nonlocal Block
Inflating 2D Networks to 3D
Inception-style architecture for 3D convnets.
Can use weights from 2D conv to initialize 3D conv: copy K_t times in Space and divide by K_t. This gives the same result as 2D conv given "constant" video input.
Weightlifting
Feichtenhofer et al, Spatiotemporal Residual Networks for Video Action Recognition, CVPR 2018

Fig: Weightlifting
Treating time and space differently: SlowFast Networks
Feichtenhofer et al, SlowFast Networks for Video Recognition, ICCV 2019
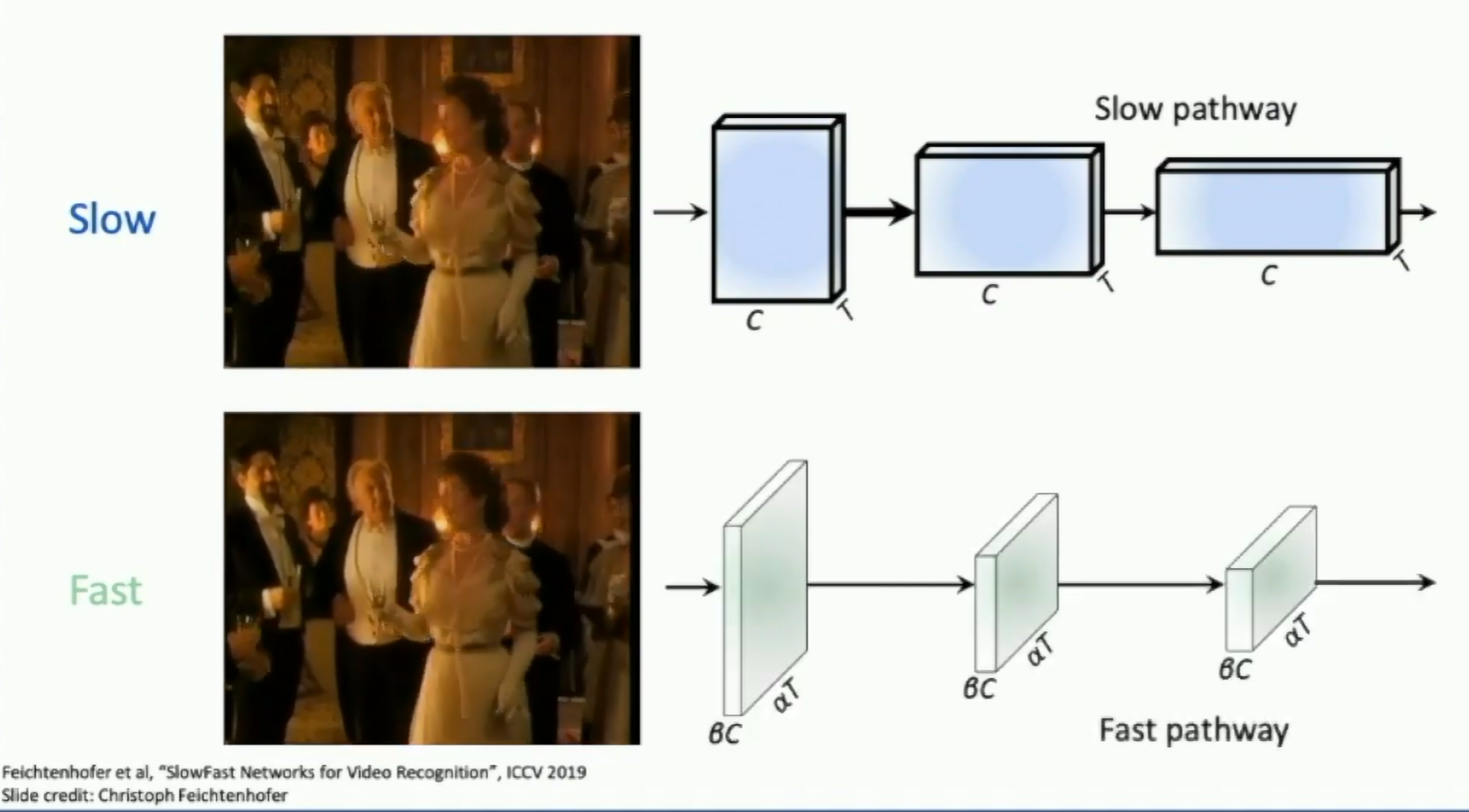
Fig: SlowFast Networks
Other task: Spatial-Temporal Detection
Given a long untrimmed video, detect all the people in space and time and classify the activities they are performing.
Some examples from AVA dataset:
Gu et al, AVA: A Video Dataset of Spatio-temporally Localized Atomic Visual Actions, CVPR 2018
Notice on Usage and Attribution
This note is based on the University of Michigan's publicly available course EECS 498.008 / 598.008 and is intended solely for personal learning and academic discussion, with no commercial use.
- Nature of the Notes: These notes include extensive references and citations from course materials to ensure clarity and completeness. However, they are presented as personal interpretations and summaries, not as substitutes for the original course content.
- Original Course Resources: Please refer to the official University of Michigan website for complete and accurate course materials.
- Third-Party Open Access Content: This note may reference Open Access (OA) papers or resources cited within the course materials. These materials are used under their original Open Access licenses (e.g., CC BY, CC BY-SA).
- Proper Attribution: Every referenced OA resource is appropriately cited, including the author, publication title, source link, and license type.
- Copyright Notice: All rights to third-party content remain with their respective authors or publishers.
- Content Removal: If you believe any content infringes on your copyright, please contact me, and I will promptly remove the content in question.
Thanks to the University of Michigan and the contributors to the course for their openness and dedication to accessible education.