UM-CV 2 Image Classification
@Credits: EECS 498.007
Personal work for the assignments of the course: github repo.
This course is basically for beginners, so I will skip basic concepts and complete the notes with copilot.
Image Classification
Problem:The semantic gap between low-level features and high-level concepts, and the computers do not have the intuition to understand the image.
Intro
Challenges
- intraclass variation
- fine-grained categories
- background clutter
- illumination change: lighting and shadow conditions
- deformatoion: the object may have various positions
- occlusion: the object may be partially covered
Scientific Applications
- medical imaging
- galaxy classification
Other Tasks in CV related to classification
- object detection: classify localized objects
- image captioning: generate a sentence to describe the image, which can be seen as a classification problem of the next-word prediction
- Playing Go: classify the next move
An Image Classifier?
def classify(image):
# Some magic here?
return labelApproaches: find edges, corners, and other features based on human knowledge... but it is not scalable.
Machine Learning: Data-driven Approach
- Collect a dataset of images and labels
- Use machine learning to train a classifier
- Evaluate the classifier on new images
def train(images, labels):
# Machine learning
return modeldef predict(model, test_image):
# Use model to predict labels
return labelDatasets
The most basic datasets: MNIST, CIFAR-10
- MNIST: handwritten digits
- CIFAR-10: 10 classes of objects
Larger datasets:
- ImageNet: 1000 classes, 1.2 million images
- COCO: 80 object categories, 300k images
- MIT Places: 205 scene categories, 2.5 million images
- LAION-5B: 5.85 billion images
Datasets are getting larger and larger, and the models are getting more and more complex.
Omniglot dataset: 1623 characters from 50 alphabets, 20 examples per character. It is used for few-shot learning. Few-shot learning is a type of machine learning that focuses on learning from a small number of examples. (小样本学习)
First Model: Nearest Neighbor
Metrics: L1 distance, L2 distance, cosine similarity
L1 distance:
L2 distance:
import numpy as np
class NearestNeighbor:
def __init__(self):
pass
def train(self, X, y):
self.Xtr = X
self.ytr = y
def predict(self, X):
num_test = X.shape[0]
Ypred = np.zeros(num_test, dtype=self.ytr.dtype)
for i in range(num_test):
distances = np.sum(np.abs(self.Xtr - X[i, :]), axis=1)
min_index = np.argmin(distances)
Ypred[i] = self.ytr[min_index]
return YpredTraining time: , Testing time:
- This is computationally expensive!
- Outliers can affect the result significantly.

Fig: outliers
Web demo: Nearest Neighbor Demo
Hyperparameters
What is the best K to use?
Hyperparameters: parameters that are not learned by the model, but are set at the start of the learning process.
Setting Hyperparameters:
- Idea 1: Choose hyperparamters that work best on the data.
- BAD: This works best on the training data.
- Idea 2: Split data into train and test and choose hyperparameters that work best on the test data.
- BAD: The algorithm is polluted by the test data!
- Idea 3: Split data into train, validation, and test. Choose hyperparameters that work best on the validation data.
- Better and correst ! We only touch once the test data.
- Bad perfomance on the test set implies bad performance on the real world.
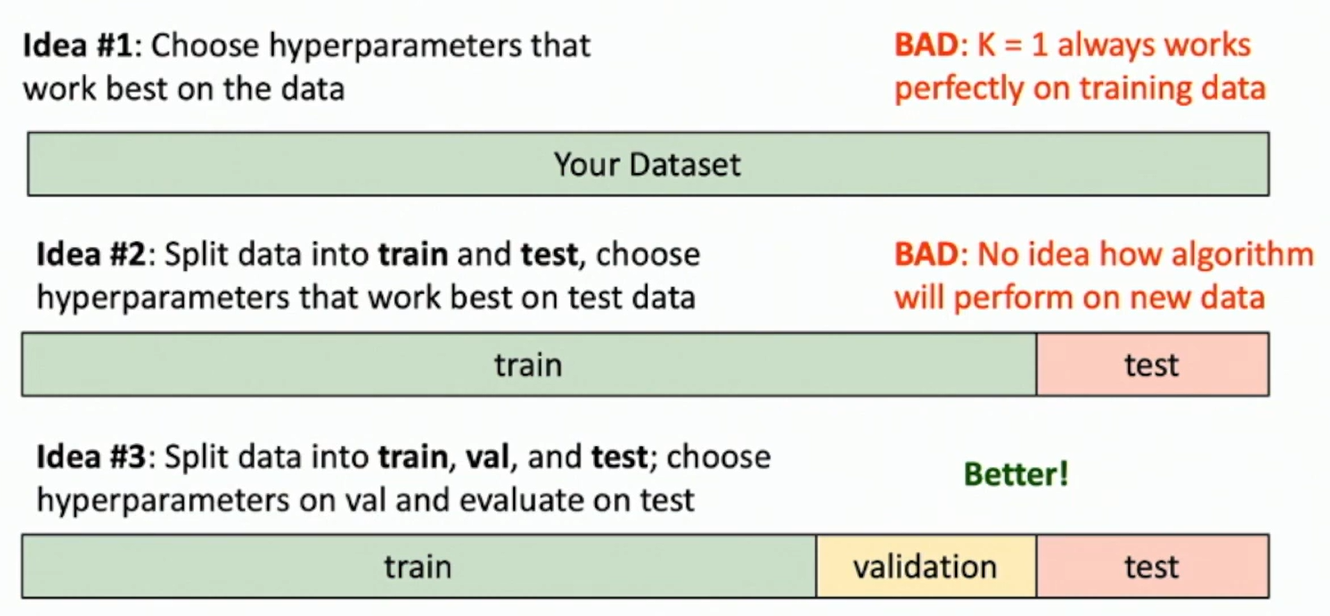
Fig: How to split your data
- Idea 4: Cross-validation: split data into k folds, train on k-1 folds, and test on the remaining fold. Repeat k times and average the results.
- Better than Idea 3, but computationally expensive. Useful for small datasets, but not used too much in deep learning.
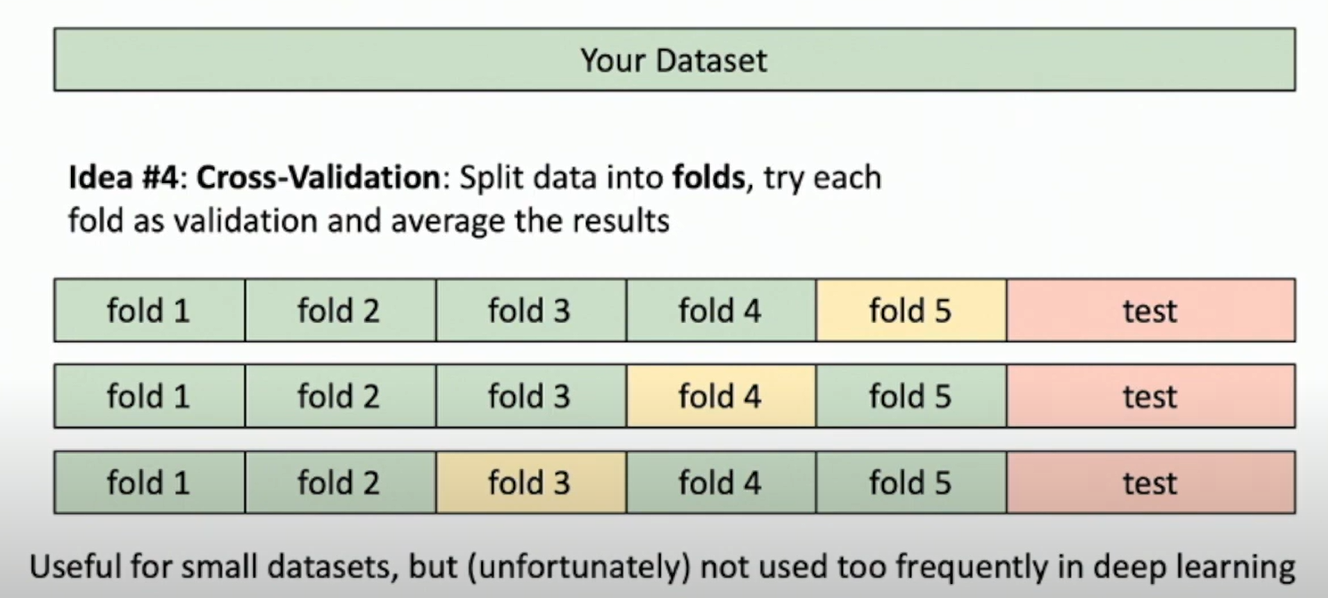
Fig: cross-validation
Emprirical studies:
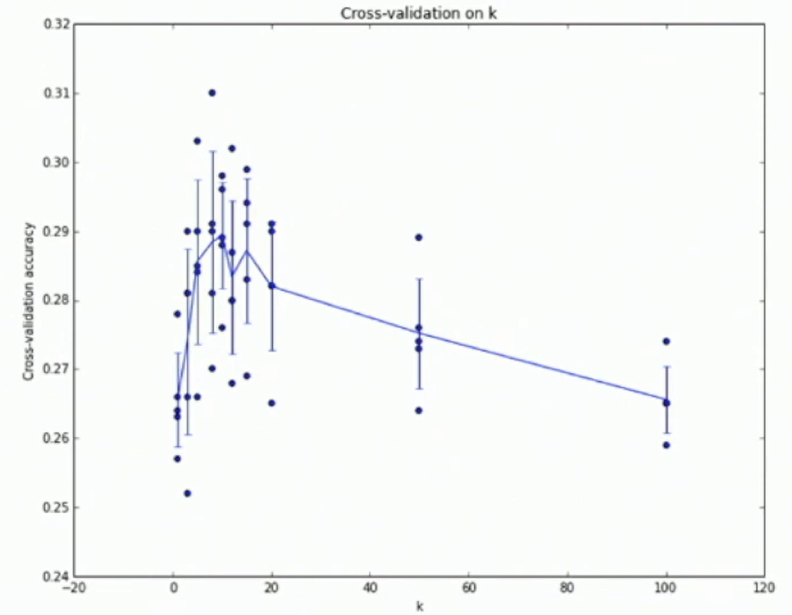
Fig: Emprirical studies
Correctness: Universal Approximation
KNN has universal approximaton power on compact sets.
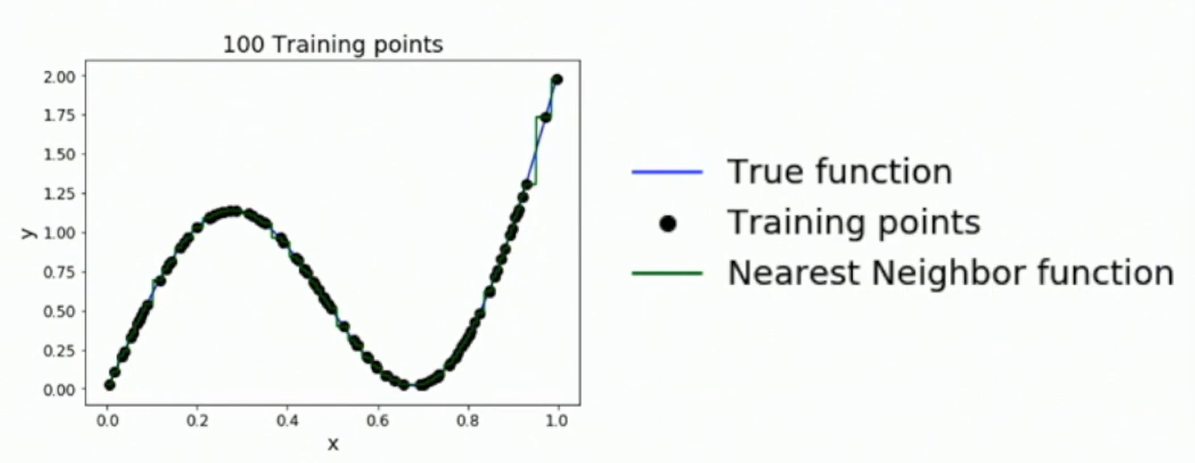
Fig: Universal Approximation
Curse of Dimensionality
As the number of (input) dimensions increases, the volume of the space increases exponentially, and the number of data points required to fill the space increases exponentially.
Summary
- KNN very is slow at runtime.
- Distance metrics on pixels are not informative, e.g. predicting a human's face based on the surrounding pixels.
- Surprisingly, KNN works well with extracted convolutional features!
Assignment 1
Some notes:
Access a single row or colums of a tensor
There are two common ways to access a single row or column of a tensor: using an integer will reduce the rank by one, and using a length-one slice will keep the same rank. Note that this is different behavior from MATLAB.
Slicing a tensor
Slicing a tensor returns a view into the same data, so modifying it will also modify the original tensor. To avoid this, you can use the clone() method to make a copy of a tensor.
When you index into torch tensor using slicing, the resulting tensor view will always be a subarray of the original tensor. This is powerful, but can be restrictive.
Indexing with an integer array or a tensor
We can also use index arrays to index tensors; this lets us construct new tensors with a lot more flexibility than using slices.
As an example, we can use index arrays to reorder the rows or columns of a tensor:
# Credit: UMich EECS 498.007
# Create the following rank 2 tensor with shape (3, 4)
# [[ 1 2 3 4]
# [ 5 6 7 8]
# [ 9 10 11 12]]
a = torch.tensor([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
print('Original tensor:')
print(a)
# Create a new tensor of shape (5, 4) by reordering rows from a:
# - First two rows same as the first row of a
# - Third row is the same as the last row of a
# - Fourth and fifth rows are the same as the second row from a
idx = [0, 0, 2, 1, 1] # index arrays can be Python lists of integers
print('\nReordered rows:')
print(a[idx])
# Create a new tensor of shape (3, 4) by reversing the columns from a
idx = torch.tensor([3, 2, 1, 0]) # Index arrays can be int64 torch tensors
print('\nReordered columns:')
print(a[:, idx])Original tensor:
tensor([[ 1, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12]])
Reordered rows:
tensor([[ 1, 2, 3, 4],
[ 1, 2, 3, 4],
[ 9, 10, 11, 12],
[ 5, 6, 7, 8],
[ 5, 6, 7, 8]])
tensor([[ 1, 2, 3, 4],
[ 1, 2, 3, 4],
[ 9, 10, 11, 12],
[ 5, 6, 7, 8],
[ 5, 6, 7, 8]])
Reordered columns:
tensor([[ 4, 3, 2, 1],
[ 8, 7, 6, 5],
[12, 11, 10, 9]])More generally, given index arrays idx0 and idx1 with N elements each, a[idx0, idx1] is equivalent to:
# Credit: UMich EECS 498.007
torch.tensor([
a[idx0[0], idx1[0]],
a[idx0[1], idx1[1]],
...,
a[idx0[N - 1], idx1[N - 1]]
])(A similar pattern extends to tensors with more than two dimensions)
# Credit: UMich EECS 498.007
We can for example use this to get or set the diagonal of a tensor:
a = torch.tensor([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
print('Original tensor:')
print(a)
idx = [0, 1, 2]
print('\nGet the diagonal:')
print(a[idx, idx])
# Modify the diagonal
a[idx, idx] = torch.tensor([11, 22, 33])
print('\nAfter setting the diagonal:')
print(a)Original tensor:
tensor([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
Get the diagonal:
tensor([1, 5, 9])
After setting the diagonal:
tensor([[11, 2, 3],
[ 4, 22, 6],
[ 7, 8, 33]])Select one element from each row or column of a tensor:
# Create a new tensor from which we will select elements
a = torch.tensor([[1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12]])
print('Original tensor:')
print(a)
# Take on element from each row of a:
# from row 0, take element 1;
# from row 1, take element 2;
# from row 2, take element 1;
# from row 3, take element 0
idx0 = torch.arange(a.shape[0]) # Quick way to build [0, 1, 2, 3]
idx1 = torch.tensor([1, 2, 1, 0])
print('\nSelect one element from each row:')
print(a[idx0, idx1])
# Now set each of those elements to zero
a[idx0, idx1] = 0
print('\nAfter modifying one element from each row:')
print(a)Original tensor:
tensor([[ 1, 2, 3],
[ 4, 5, 6],
[ 7, 8, 9],
[10, 11, 12]])
Select one element from each row:
tensor([ 2, 6, 8, 10])
After modifying one element from each row:
tensor([[ 1, 0, 3],
[ 4, 5, 0],
[ 7, 0, 9],
[ 0, 11, 12]])Boolean masking of tensors
The shape of the boolean mask should be the same as the original tensor, or should be broadcastable to the same shape. This is commnly used so I will not detail it here.
Contiguous ?
Some combinations of reshaping operations will fail with cryptic errors. The exact reasons for this have to do with the way that tensors and views of tensors are implemented, and are beyond the scope of this assignment. However if you're curious, this blog post by Edward Yang gives a clear explanation of the problem.
pytorch-internals is a good blog to understand the operation contiguous(), view() and reshape().
KNN
Recall: some useful functions in PyTorch
torch.view
torch.reshape
torch.flatten
torch.permute
torch.transpose
torch.squeeze
torch.unsqueeze
torch.argmax
torch.topk
torch.sort
torch.argsort
torch.mm
torch.mv
torch.einsum
torch.cat
torch.chunkKNN Implementation
"""
Implements a K-Nearest Neighbor classifier in PyTorch.
"""
import torch
from typing import Dict, List
def hello():
"""
This is a sample function that we will try to import and run to ensure that
our environment is correctly set up on Google Colab.
"""
print("Hello from knn.py!")
def compute_distances_two_loops(x_train: torch.Tensor, x_test: torch.Tensor):
"""
Computes the squared Euclidean distance between each element of training
set and each element of test set. Images should be flattened and treated
as vectors.
This implementation uses a naive set of nested loops over the training and
test data.
The input data may have any number of dimensions -- for example this
function should be able to compute nearest neighbor between vectors, in
which case the inputs will have shape (num_{train, test}, D); it should
also be able to compute nearest neighbors between images, where the inputs
will have shape (num_{train, test}, C, H, W). More generally, the inputs
will have shape (num_{train, test}, D1, D2, ..., Dn); you should flatten
each element of shape (D1, D2, ..., Dn) into a vector of shape
(D1 * D2 * ... * Dn) before computing distances.
The input tensors should not be modified.
NOTE: Your implementation may not use `torch.norm`, `torch.dist`,
`torch.cdist`, or their instance method variants (`x.norm`, `x.dist`,
`x.cdist`, etc.). You may not use any functions from `torch.nn` or
`torch.nn.functional` modules.
Args:
x_train: Tensor of shape (num_train, D1, D2, ...)
x_test: Tensor of shape (num_test, D1, D2, ...)
Returns:
dists: Tensor of shape (num_train, num_test) where dists[i, j]
is the squared Euclidean distance between the i-th training point
and the j-th test point. It should have the same dtype as x_train.
"""
# Initialize dists to be a tensor of shape (num_train, num_test) with the
# same datatype and device as x_train
num_train = x_train.shape[0]
num_test = x_test.shape[0]
dists = x_train.new_zeros(num_train, num_test)
##########################################################################
# TODO: Implement this function using a pair of nested loops over the #
# training data and the test data. #
# #
# You may not use torch.norm (or its instance method variant), nor any #
# functions from torch.nn or torch.nn.functional. #
##########################################################################
# Replace "pass" statement with your code
for i in range(num_train):
for j in range(num_test):
dists[i, j] = torch.sum((x_train[i] - x_test[j])**2)
##########################################################################
# END OF YOUR CODE #
##########################################################################
return dists
def compute_distances_one_loop(x_train: torch.Tensor, x_test: torch.Tensor):
"""
Computes the squared Euclidean distance between each element of training
set and each element of test set. Images should be flattened and treated
as vectors.
This implementation uses only a single loop over the training data.
Similar to `compute_distances_two_loops`, this should be able to handle
inputs with any number of dimensions. The inputs should not be modified.
NOTE: Your implementation may not use `torch.norm`, `torch.dist`,
`torch.cdist`, or their instance method variants (`x.norm`, `x.dist`,
`x.cdist`, etc.). You may not use any functions from `torch.nn` or
`torch.nn.functional` modules.
Args:
x_train: Tensor of shape (num_train, D1, D2, ...)
x_test: Tensor of shape (num_test, D1, D2, ...)
Returns:
dists: Tensor of shape (num_train, num_test) where dists[i, j]
is the squared Euclidean distance between the i-th training point
and the j-th test point. It should have the same dtype as x_train.
"""
# Initialize dists to be a tensor of shape (num_train, num_test) with the
# same datatype and device as x_train
##########################################################################
# TODO: Implement this function using only a single loop over x_train. #
# #
# You may not use torch.norm (or its instance method variant), nor any #
# functions from torch.nn or torch.nn.functional. #
##########################################################################
# Replace "pass" statement with your code
num_train = x_train.shape[0]
num_test = x_test.shape[0]
dists = torch.zeros(num_train, num_test,
dtype=x_train.dtype,
device=x_train.device)
for i in range(num_train):
dists[i] = torch.sum((x_train[i] - x_test)**2, dim=(1, 2, 3))
##########################################################################
# END OF YOUR CODE #
##########################################################################
return dists
def compute_distances_no_loops(x_train: torch.Tensor, x_test: torch.Tensor):
"""
Computes the squared Euclidean distance between each element of training
set and each element of test set. Images should be flattened and treated
as vectors.
This implementation should not use any Python loops. For memory-efficiency,
it also should not create any large intermediate tensors; in particular you
should not create any intermediate tensors with O(num_train * num_test)
elements.
Similar to `compute_distances_two_loops`, this should be able to handle
inputs with any number of dimensions. The inputs should not be modified.
NOTE: Your implementation may not use `torch.norm`, `torch.dist`,
`torch.cdist`, or their instance method variants (`x.norm`, `x.dist`,
`x.cdist`, etc.). You may not use any functions from `torch.nn` or
`torch.nn.functional` modules.
Args:
x_train: Tensor of shape (num_train, C, H, W)
x_test: Tensor of shape (num_test, C, H, W)
Returns:
dists: Tensor of shape (num_train, num_test) where dists[i, j] is
the squared Euclidean distance between the i-th training point and
the j-th test point.
"""
# Initialize dists to be a tensor of shape (num_train, num_test) with the
# same datatype and device as x_train
num_train = x_train.shape[0]
num_test = x_test.shape[0]
##########################################################################
# TODO: Implement this function without using any explicit loops and #
# without creating any intermediate tensors with O(num_train * num_test) #
# elements. #
# #
# You may not use torch.norm (or its instance method variant), nor any #
# functions from torch.nn or torch.nn.functional. #
# #
# HINT: Try to formulate the Euclidean distance using two broadcast sums #
# and a matrix multiply. #
##########################################################################
# Replace "pass" statement with your code
dists = torch.sum((x_train.view(num_train, 1, -1) -
x_test.view(num_test, 1, -1).permute(1, 0, 2))**2, dim=2)
# dists = torch.cdist(x_train.view(num_train, -1),
# x_test.view(num_test, -1), p=2)
##########################################################################
# END OF YOUR CODE #
##########################################################################
return dists
def predict_labels(dists: torch.Tensor, y_train: torch.Tensor, k: int = 1):
"""
Given distances between all pairs of training and test samples, predict a
label for each test sample by taking a MAJORITY VOTE among its `k` nearest
neighbors in the training set.
In the event of a tie, this function SHOULD return the smallest label. For
example, if k=5 and the 5 nearest neighbors to a test example have labels
[1, 2, 1, 2, 3] then there is a tie between 1 and 2 (each have 2 votes),
so we should return 1 since it is the smallest label.
This function should not modify any of its inputs.
Args:
dists: Tensor of shape (num_train, num_test) where dists[i, j] is the
squared Euclidean distance between the i-th training point and the
j-th test point.
y_train: Tensor of shape (num_train,) giving labels for all training
samples. Each label is an integer in the range [0, num_classes - 1]
k: The number of nearest neighbors to use for classification.
Returns:
y_pred: int64 Tensor of shape (num_test,) giving predicted labels for
the test data, where y_pred[j] is the predicted label for the j-th
test example. Each label should be an integer in the range
[0, num_classes - 1].
"""
num_train, num_test = dists.shape
y_pred = torch.zeros(num_test, dtype=torch.int64)
##########################################################################
# TODO: Implement this function. You may use an explicit loop over the #
# test samples. #
# #
# HINT: Look up the function torch.topk #
##########################################################################
# Replace "pass" statement with your code
neighbor_indices = torch.topk(dists, k=k, dim=0, largest=False).indices
y_neighbors = y_train[neighbor_indices]
y_pred = torch.mode(y_neighbors, 0).values
##########################################################################
# END OF YOUR CODE #
##########################################################################
return y_pred
class KnnClassifier:
def __init__(self, x_train: torch.Tensor, y_train: torch.Tensor):
"""
Create a new K-Nearest Neighbor classifier with the specified training
data. In the initializer we simply memorize the provided training data.
Args:
x_train: Tensor of shape (num_train, C, H, W) giving training data
y_train: int64 Tensor of shape (num_train, ) giving training labels
"""
######################################################################
# TODO: Implement the initializer for this class. It should perform #
# no computation and simply memorize the training data in #
# `self.x_train` and `self.y_train`, accordingly. #
######################################################################
# Replace "pass" statement with your code
self.x_train = x_train
self.y_train = y_train
######################################################################
# END OF YOUR CODE #
######################################################################
def predict(self, x_test: torch.Tensor, k: int = 1):
"""
Make predictions using the classifier.
Args:
x_test: Tensor of shape (num_test, C, H, W) giving test samples.
k: The number of neighbors to use for predictions.
Returns:
y_test_pred: Tensor of shape (num_test,) giving predicted labels
for the test samples.
"""
y_test_pred = None
######################################################################
# TODO: Implement this method. You should use the functions you #
# wrote above for computing distances (use the no-loop variant) and #
# to predict output labels. #
######################################################################
# Replace "pass" statement with your code
dist = compute_distances_no_loops(self.x_train, x_test)
y_test_pred = predict_labels(dist, self.y_train, k)
######################################################################
# END OF YOUR CODE #
######################################################################
return y_test_pred
def check_accuracy(
self,
x_test: torch.Tensor,
y_test: torch.Tensor,
k: int = 1,
quiet: bool = False
):
"""
Utility method for checking the accuracy of this classifier on test
data. Returns the accuracy of the classifier on the test data, and
also prints a message giving the accuracy.
Args:
x_test: Tensor of shape (num_test, C, H, W) giving test samples.
y_test: int64 Tensor of shape (num_test,) giving test labels.
k: The number of neighbors to use for prediction.
quiet: If True, don't print a message.
Returns:
accuracy: Accuracy of this classifier on the test data, as a
percent. Python float in the range [0, 100]
"""
y_test_pred = self.predict(x_test, k=k)
num_samples = x_test.shape[0]
num_correct = (y_test == y_test_pred).sum().item()
accuracy = 100.0 * num_correct / num_samples
msg = (
f"Got {num_correct} / {num_samples} correct; "
f"accuracy is {accuracy:.2f}%"
)
if not quiet:
print(msg)
return accuracy
def knn_cross_validate(
x_train: torch.Tensor,
y_train: torch.Tensor,
num_folds: int = 5,
k_choices: List[int] = [1, 3, 5, 8, 10, 12, 15, 20, 50, 100],
):
"""
Perform cross-validation for `KnnClassifier`.
Args:
x_train: Tensor of shape (num_train, C, H, W) giving all training data.
y_train: int64 Tensor of shape (num_train,) giving labels for training
data.
num_folds: Integer giving the number of folds to use.
k_choices: List of integers giving the values of k to try.
Returns:
k_to_accuracies: Dictionary mapping values of k to lists, where
k_to_accuracies[k][i] is the accuracy on the i-th fold of a
`KnnClassifier` that uses k nearest neighbors.
"""
# First we divide the training data into num_folds equally-sized folds.
x_train_folds = []
y_train_folds = []
##########################################################################
# TODO: Split the training data and images into folds. After splitting, #
# x_train_folds and y_train_folds should be lists of length num_folds, #
# where y_train_folds[i] is label vector for images inx_train_folds[i]. #
# #
# HINT: torch.chunk #
##########################################################################
# Replace "pass" statement with your code
x_train_folds = torch.chunk(x_train, num_folds, dim=0)
y_train_folds = torch.chunk(y_train, num_folds, dim=0)
##########################################################################
# END OF YOUR CODE #
##########################################################################
# A dictionary holding the accuracies for different values of k that we
# find when running cross-validation. After running cross-validation,
# k_to_accuracies[k] should be a list of length num_folds giving the
# different accuracies we found trying `KnnClassifier`s using k neighbors.
k_to_accuracies = {}
##########################################################################
# TODO: Perform cross-validation to find the best value of k. For each #
# value of k in k_choices, run the k-NN algorithm `num_folds` times; in #
# each case you'll use all but one fold as training data, and use the #
# last fold as a validation set. Store the accuracies for all folds and #
# all values in k in k_to_accuracies. #
# #
# HINT: torch.cat #
##########################################################################
# Replace "pass" statement with your code
for k in k_choices:
k_to_accuracies[k] = []
for i in range(num_folds):
x_train_fold = torch.cat(
x_train_folds[:i] + x_train_folds[i+1:], dim=0)
y_train_fold = torch.cat(
y_train_folds[:i] + y_train_folds[i+1:], dim=0)
x_val_fold = x_train_folds[i]
y_val_fold = y_train_folds[i]
knn = KnnClassifier(x_train_fold, y_train_fold)
accuracy = knn.check_accuracy(
x_val_fold, y_val_fold, k=k, quiet=True)
k_to_accuracies[k].append(accuracy)
##########################################################################
# END OF YOUR CODE #
##########################################################################
return k_to_accuracies
def knn_get_best_k(k_to_accuracies: Dict[int, List]):
"""
Select the best value for k, from the cross-validation result from
knn_cross_validate. If there are multiple k's available, then you SHOULD
choose the smallest k among all possible answer.
Args:
k_to_accuracies: Dictionary mapping values of k to lists, where
k_to_accuracies[k][i] is the accuracy on the i-th fold of a
`KnnClassifier` that uses k nearest neighbors.
Returns:
best_k: best (and smallest if there is a conflict) k value based on
the k_to_accuracies info.
"""
best_k = 0
##########################################################################
# TODO: Use the results of cross-validation stored in k_to_accuracies to #
# choose the value of k, and store result in `best_k`. You should choose #
# the value of k that has the highest mean accuracy accross all folds. #
##########################################################################
# Replace "pass" statement with your code
best_accuracy = 0
for k, accuracies in k_to_accuracies.items():
accuracy = sum(accuracies) / len(accuracies)
if accuracy > best_accuracy:
best_accuracy = accuracy
best_k = k
##########################################################################
# END OF YOUR CODE #
##########################################################################
return best_k