Batch Normalization backpropagation using differential forms - Matrix Gradient by hand in Deep Learning (2)
For the rules of matrix differentiation, please refer to the previous article: Calculate the gradient of a matrix by hand in deep learning
Recall of essential rules
Let be a matrix of size , and be a scalar function of .
In higher order notation, we introduce the concept of differentials. If is differentiable, then for a small change in the matrix , we have
where is a small change (well actually this is a linear functional) in the element .
And we define the matrix of partial derivatives as
Then we can write the differential as a Frobenius product:
Important Frobenius productWe will use this following formula many times in the next sections.
We can write as a Frobenius product of the gradient of and the differential of .
This is obtained by the fact that .
where is a matrix of the same shape as , representing the differential (or a small variation) of .
Differential rules
TricksIf is invertible, then we have
Element-wise operations:
Element-wise functions:
Trace rules
Tricks
- Scalar rule: if is a scalar, then .
- Transpose rule: .
- Linearity: .
- Cyclic rule: .
- Product rule: .
Batch normalization differentiation by hand
The gradient of batch normalization is notoriously difficult to calculate. Our method simplify the calculation of the gradient of batch normalization, and we will just apply the rules.
We will define the following variables:
- : input data,
- : mean of , , a row vector
- : variance of , , a row vector
- : normalized data,
- : a column vector of ones,
- : loss function,
As well as the following parameters:
- : scale parameter, , a row vector
- : shift parameter, , a row vector
Forward pass
The forward pass of batch normalization is as follows:
Vectorized form:
The computational graph is shown below:
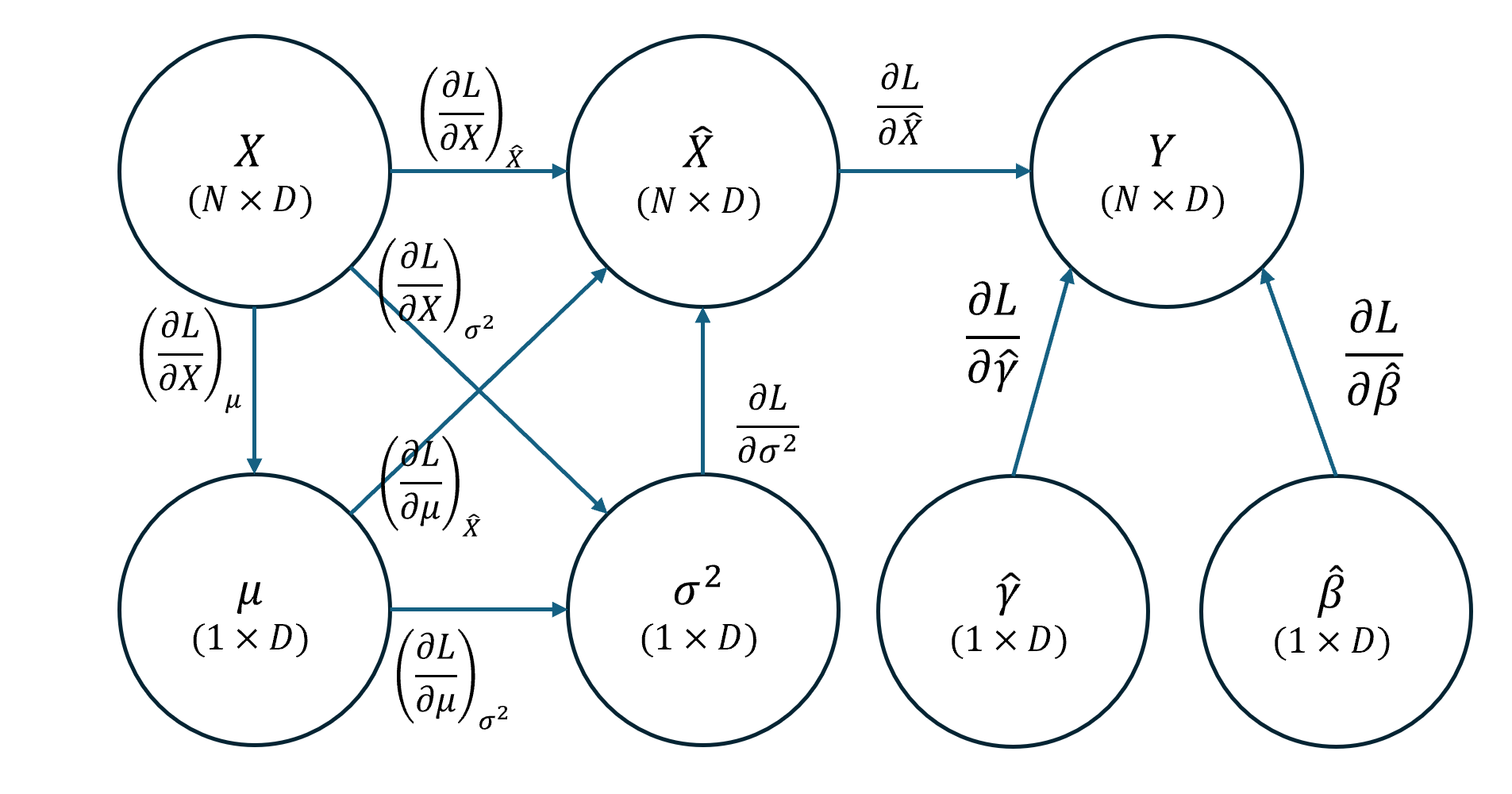
Fig: Computational graph
Backward pass
Suppose we have the upstream gradient
Step 1: Backpropagate Y
Calculate , ,
Recall the formula of :
We have the differential of :
We can write the differential of as a Frobenius product:
For the first term, we have:
Thus,
For the second term, we have:
by applying the product rule, we have:
Thus
For the third term, similarly, we have:
Step 2: Backpropagate X_hat
Now that we have , we can calculate and .
Recall the rules:
and the definition of :
we have
Abuse of notation: we will use to denote a part of the real , since wo do not care about the differential with respect to and
Meanwhile, we have
by developing , we have
where we can clearly see , and . But be careful contains . And since the differential is linear, we add all gradients together later on.
Continue developing the formula above, we have
The first term gives a part of the gradient of :
Thus,
The second term gives a part of the gradient of :
Thus,
The third term gives the gradient of :
Thus
Step 3: Backpropagate σ2
Recall the formula of :
Hence,
Therefore,
For the first term, we got the second part of the gradient of :
For the second term, we got the second part of the gradient of :
Step 4: Backpropagate μ
Now we have :
Recall the formula of :
Hence,
Therefore,
Thus,
Final Step: Gradient of X
Finally, we have the gradient of :
Summary
Fig: Computational graph
Backpropagate :
Backpropagate :
Backpropagate :
Backpropagate :
Finally, we have the gradient of :
Implementation
# Credits: This code is based on the assignment from UMich EECS 498-007/598-005 assignment 3
import torch
class BatchNorm(object):
@ staticmethod
def forward(x, gamma, beta, bn_param):
"""
Forward pass for batch normalization.
During training the sample mean and (uncorrected) sample variance
are computed from minibatch statistics and used to normalize the
incoming data. During training we also keep an exponentially decaying
running mean of the mean and variance of each feature, and these
averages are used to normalize data at test-time.
At each timestep we update the running averages for mean and
variance using an exponential decay based on the momentum parameter:
running_mean = momentum * running_mean + (1 - momentum) * sample_mean
running_var = momentum * running_var + (1 - momentum) * sample_var
Note that the batch normalization paper suggests a different
test-time behavior: they compute sample mean and variance for
each feature using a large number of training images rather than
using a running average. For this implementation we have chosen to use
running averages instead since they do not require an additional
estimation step; the PyTorch implementation of batch normalization
also uses running averages.
Input:
- x: Data of shape (N, D)
- gamma: Scale parameter of shape (D,)
- beta: Shift parameter of shape (D,)
- bn_param: Dictionary with the following keys:
- mode: 'train' or 'test'; required
- eps: Constant for numeric stability
- momentum: Constant for running mean / variance.
- running_mean: Array of shape (D,) giving running mean
of features
- running_var Array of shape (D,) giving running variance
of features
Returns a tuple of:
- out: of shape (N, D)
- cache: A tuple of values needed in the backward pass
"""
mode = bn_param['mode']
eps = bn_param.get('eps', 1e-5)
momentum = bn_param.get('momentum', 0.9)
N, D = x.shape
# 如果字典中没有这两个 key,就返回 0
# 但字典里并没有把对应的 key 添加进去
running_mean = bn_param.get('running_mean',
torch.zeros(D,
dtype=x.dtype,
device=x.device))
running_var = bn_param.get('running_var',
torch.zeros(D,
dtype=x.dtype,
device=x.device))
out, cache = None, None
if mode == 'train':
##################################################################
# TODO: Implement the training-time forward pass for batch norm. #
# Use minibatch statistics to compute the mean and variance, use #
# these statistics to normalize the incoming data, and scale and #
# shift the normalized data using gamma and beta. #
# #
# You should store the output in the variable out. #
# Any intermediates that you need for the backward pass should #
# be stored in the cache variable. #
# #
# You should also use your computed sample mean and variance #
# together with the momentum variable to update the running mean #
# and running variance, storing your result in the running_mean #
# and running_var variables. #
# #
# Note that though you should be keeping track of the running #
# variance, you should normalize the data based on the standard #
# deviation (square root of variance) instead! #
# Referencing the original paper #
# (https://arxiv.org/abs/1502.03167) might prove to be helpful. #
##################################################################
# Replace "pass" statement with your code
# Compute the mean and variance of the mini-batch
mean = x.mean(dim=0)
var = x.var(dim=0, unbiased=False)
std = torch.sqrt(var + eps)
x_hat = (x - mean) / std
out = gamma * x_hat + beta
# Update cache
cache = (x, mean, var, std, x_hat, gamma, beta, eps, mode)
# Update running mean and variance
# Wrong code
# bn_param['running_mean'] = momentum * \
# mean + (1 - momentum) * running_mean
# bn_param['running_var'] = momentum * \
# var + (1 - momentum) * running_var
# Correct code
# Why ? Because the professor has done the storage below !!!
# And his implementation has rewritten what I have done...
# I have been stuck here for a long time...
# Read through the code before you start coding...
running_mean = (1 - momentum) * mean + momentum * running_mean
running_var = (1 - momentum) * var + momentum * running_var
################################################################
# END OF YOUR CODE #
################################################################
elif mode == 'test':
################################################################
# TODO: Implement the test-time forward pass for #
# batch normalization. Use the running mean and variance to #
# normalize the incoming data, then scale and shift the #
# normalized data using gamma and beta. Store the result #
# in the out variable. #
################################################################
# Replace "pass" statement with your code
std = torch.sqrt(running_var + eps)
x_hat = (x - running_mean)
out = gamma * x_hat + beta
cache = (x, running_mean, running_var, std,
x_hat, gamma, beta, eps, mode)
################################################################
# END OF YOUR CODE #
################################################################
else:
raise ValueError('Invalid forward batchnorm mode "%s"' % mode)
# Store the updated running means back into bn_param
bn_param['running_mean'] = running_mean.detach()
bn_param['running_var'] = running_var.detach()
return out, cache
@ staticmethod
def backward(dout, cache):
"""
Backward pass for batch normalization.
For this implementation, you should write out a
computation graph for batch normalization on paper and
propagate gradients backward through intermediate nodes.
Inputs:
- dout: Upstream derivatives, of shape (N, D)
- cache: Variable of intermediates from batchnorm_forward.
Returns a tuple of:
- dx: Gradient with respect to inputs x, of shape (N, D)
- dgamma: Gradient with respect to scale parameter gamma,
of shape (D,)
- dbeta: Gradient with respect to shift parameter beta,
of shape (D,)
"""
dx, dgamma, dbeta = None, None, None
#####################################################################
# TODO: Implement the backward pass for batch normalization. #
# Store the results in the dx, dgamma, and dbeta variables. #
# Referencing the original paper (https://arxiv.org/abs/1502.03167) #
# might prove to be helpful. #
# Don't forget to implement train and test mode separately. #
#####################################################################
# Replace "pass" statement with your code
mode = cache[-1]
if mode == 'train':
x, mean, var, std, x_hat, gamma, beta, eps = cache[:-1]
# var = x.var(dim=0, unbiased=False)
# mean = x.mean(dim=0)
# x_hat = (x - mean) / torch.sqrt(var + eps)
# out = gamma * x_hat + beta
N, D = x.shape
dbeta = dout.sum(dim=0)
dgamma = (dout * x_hat).sum(dim=0)
dx_hat = dout * gamma
dx = dx_hat / std
dmu = -dx_hat.sum(dim=0) / std
dsigma2 = torch.sum(-0.5 * dx_hat * x_hat / (std ** 2), dim=0)
dmu += dsigma2 * torch.mean(-2 * (x - mean), dim=0)
dx += dmu / N
dx += dsigma2 * 2 * (x - mean) / N
elif mode == 'test':
x, running_mean, running_var, std, x_hat, gamma, beta, eps = cache
dbeta = dout.sum(dim=0)
dgamma = (dout * x_hat).sum(dim=0)
dx_hat = dout * gamma
dx = dx_hat / std
#################################################################
# END OF YOUR CODE #
#################################################################
return dx, dgamma, dbeta
@ staticmethod
def backward_alt(dout, cache):
"""
Alternative backward pass for batch normalization.
For this implementation you should work out the derivatives
for the batch normalization backward pass on paper and simplify
as much as possible. You should be able to derive a simple expression
for the backward pass. See the jupyter notebook for more hints.
Note: This implementation should expect to receive the same
cache variable as batchnorm_backward, but might not use all of
the values in the cache.
Inputs / outputs: Same as batchnorm_backward
"""
dx, dgamma, dbeta = None, None, None
###################################################################
# TODO: Implement the backward pass for batch normalization. #
# Store the results in the dx, dgamma, and dbeta variables. #
# #
# After computing the gradient with respect to the centered #
# inputs, you should be able to compute gradients with respect to #
# the inputs in a single statement; our implementation fits on a #
# single 80-character line. #
###################################################################
# Replace "pass" statement with your code
x, mean, var, std, x_hat, gamma, beta, eps, mode = cache
N, D = x.shape
if mode == 'train':
dbeta = dout.sum(dim=0)
dgamma = (dout * x_hat).sum(dim=0)
dx_hat = dout * gamma
dx = (dx_hat - dx_hat.mean(dim=0) -
x_hat * (dx_hat * x_hat).mean(dim=0)) / std
elif mode == 'test':
dbeta = dout.sum(dim=0)
dgamma = (dout * x_hat).sum(dim=0)
dx = dout * gamma / std
#################################################################
# END OF YOUR CODE #
#################################################################
return dx, dgamma, dbeta